商务合作 电话:17719878617
“具有执行感知功能(例如感知,学习,推理和解决问题)的能力的机器被认为拥有人工智能。当机器具有认知能力时,就会存在人工智能。 判断AI的基准是涉及推理、语音和视觉是否接近或达到人类水平。”

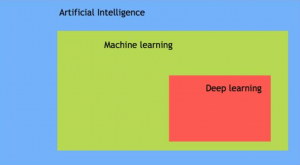
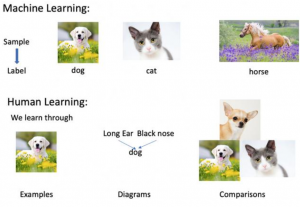
一、入门人工智能 弱AI(Narrow AI):当机器可以比人类更好地执行特定任务时。 通用AI(General AI):人工智能可以以与人类相同的精度水平执行任何智力任务时达到通用状态。 强AI(Strong AI):当AI在许多任务中都能击败人类时,它就是强AI。 如今,人工智能已在几乎所有行业中使用,为所有大规模集成人工智能的公司提供了技术优势。麦肯锡认为,与其他分析技术相比,人工智能有潜力创造6000亿美元的零售价值,为银行业带来50%的增量价值。在运输和物流领域,潜在收入增长了89%以上。 具体来说,如果企业将AI用于其营销团队,则可以使平凡而又重复性的任务自动化,从而使销售代表可以专注于诸如建立关系,培养领导等任务。企业可以使用AI分析和推荐来制定制胜战略。 简而言之,人工智能提供了一种尖端技术来处理人类无法处理的复杂数据。 AI将多余的工作自动化,使工人可以专注于高水平的增值任务。大规模实施AI可以降低成本并增加收入。 二、人工智能简史 如今,人工智能已成为流行语,尽管这个术语并不新鲜。 1956年,一群来自不同背景的前卫专家决定组织有关AI的夏季研究项目。 四个聪明的人领导了这个项目。 John McCarthy(达特茅斯学院),Marvin Minsky(哈佛大学),Nathaniel Rochester(IBM)和Claude Shannon(贝尔电话实验室)。该研究项目的主要目的是解决“原则上可以精确地描述出学习的每一个方面或智能的任何其他特征,从而可以制造出机器来对其进行仿真”。 这次会议的提议包括: 1)自动电脑 2)如何将计算机编程为使用某种语言? 3)神经元网 4)自我提升 这导致了可以创建智能计算机的想法。 充满希望的新时代开始了-人工智能。 三、人工智能类型: 人工智能可以分为三个子领域: 1)人工智能 2)机器学习 3)深度学习 四、什么是机器学习? 机器学习是研究从示例和经验中学习的算法的艺术。机器学习基于这样的想法,即数据中存在一些已识别的模式,可用于将来的预测。与硬编程规则的区别在于,机器会自行学习以找到此类规则。 五、什么是深度学习? 深度学习是机器学习的一个子领域。深度学习并不意味着机器学习更多的深入知识;而是意味着机器使用不同的层从数据中学习。模型的深度由模型中的层数表示。例如,用于图像识别的Google LeNet模型有22层。在深度学习中,学习阶段是通过神经网络完成的。神经网络是一种结构,其中各层相互堆叠。 六、人工智能与机器学习 我们大多数的智能手机,日常设备甚至互联网都使用人工智能。想要宣布其最新创新的大公司通常会交替使用AI和机器学习。但是,机器学习和AI在某些方面有所不同。 AI(人工智能)是训练机器执行人类任务的科学。这个术语是在1950年代发明的,当时科学家开始研究计算机如何自行解决问题。 人工智能是一台具有类人特性的计算机。它可以轻松,无缝地计算我们周围的世界。人工智能是计算机可以执行相同操作的概念。可以说,人工智能是模仿人类能力的大型科学。 机器学习是AI的一个独特子集,它可以训练机器如何学习。机器学习模型会寻找数据中的模式,然后尝试得出结论。简而言之,无需人工对机器进行编程。程序员提供了一些示例,计算机将从这些示例中学习如何做。 七、AI都在哪里使用? 人工智能具有广泛的应用: 人工智能用于减少或避免重复任务。例如,AI可以连续重复任务,而不会感到疲劳。实际上,人工智能永远不会停止,对执行的任务无关紧要。 人工智能改善了现有产品。在机器学习时代之前,核心产品是建立在硬编程规则之上的。公司引入人工智能来增强产品的功能,而不是从头开始设计新产品。你可以想到一些社交平台的照片。几年前,你必须手动标记朋友。如今,在AI的帮助下,社交平台给你推荐朋友。 从市场营销到供应链,金融,食品加工等行业,人工智能被广泛应用。根据麦肯锡的一项调查,金融服务和高科技通信在AI领域处于领先地位。 八、为什么AI蓬勃发展? 自90年代以来,随着Yann LeCun的开创性论文出现了神经网络。但是,它在2012年左右开始变得出名。对其受欢迎程度的三个关键因素解释为: 1)硬件 2)数据 3)算法 机器学习是一个实验领域,这意味着它需要有数据来测试新的思想或方法。随着互联网的繁荣,数据变得更加易于访问。此外,像NVIDIA和AMD这样的大公司也为游戏市场开发了高性能的图形芯片。 1.硬件 在过去的二十年中,CPU的功能爆炸性增长,使用户可以在任何笔记本电脑上训练小型的深度学习模型。但是,要处理用于计算机视觉或深度学习的深度学习模型,你需要一台功能更强大的机器。多亏了NVIDIA和AMD的投资,新一代GPU(图形处理单元)才问世。这些芯片允许并行计算。这意味着机器可以在多个GPU上分离计算以加快计算速度。 例如,使用NVIDIA TITAN X,需要花两天的时间来为传统CPU训练数周的ImageNet模型。此外,大公司使用GPU集群通过NVIDIA Tesla K80训练深度学习模型,因为它有助于降低数据中心成本并提供更好的性能。 2.数据 深度学习是模型的结构,而数据则是使其活跃的基础。数据为人工智能提供动力。没有数据,什么也做不了。最新技术已经突破了数据存储的界限。在数据中心中存储大量数据比以往任何时候都更加容易。 互联网革命使数据收集和分发可用于馈送机器学习算法。如果你熟悉Instagram或其他任何带有图像的应用程序,则可以猜测它们的AI潜力。这些网站上有数以百万计的带有标签的照片。这些图片可用于训练神经网络模型以识别图片上的对象,而无需手动收集和标记数据。 人工智能与数据结合是新的黄金时代。数据是任何公司都不应忽视的独特竞争优势。 AI从你的数据中提供最佳答案。如果所有公司都可以使用相同的技术,那么拥有数据的公司将比其他公司具有竞争优势。举个例子,世界每天创造约2.2 EB,即22亿千兆字节。公司需要异常多样化的数据源,以便能够找到模式并进行大量学习。 3.算法 硬件比以往任何时候都更加强大,可以轻松访问数据,但是使神经网络更可靠的一件事是开发了更精确的算法。初级神经网络是没有深度统计特性的简单乘法矩阵。自2010年以来,在改善神经网络方面取得了令人瞩目的发现。人工智能使用渐进式学习算法来让数据进行编程。这意味着,计算机可以自学如何执行不同的任务,例如发现异常,成为聊天机器人。 九、总结 人工智能和机器学习是两个令人困惑的术语。人工智能是训练机器模仿或复制人类任务的科学。科学家可以使用不同的方法来训练机器。在AI时代的初期,程序员编写了硬编程的程序,即键入机器可以面对的每一种逻辑可能性以及如何响应。当系统变得复杂时,很难管理规则。为了克服这个问题,机器可以使用数据来学习如何处理给定环境中的所有情况。 拥有强大的AI的最重要功能是拥有足够多的数据,并且异构性强。例如,一台机器只要有足够的单词可以学习就可以学习不同的语言。AI是新的尖端技术。麦肯锡估计,人工智能可以以至少两位数的速度推动每个行业的发展。