
商务合作 电话:17719878617
电商环境中,商品的图片展示比文字展示对顾客购买有更直观的吸引力,尤其在购买衣服时。阿里巴巴的百万卖家各个都是ps大师,想必大家都领教过^_^。
传统的方法需要富有经验的设计师交互式的抠图,效率低下,阿里巴巴的视觉研究团队希望使用技术手段帮助卖家一键完成非幕布的自然场景人物抠图。
发表于ACM MM2018会议的论文《Semantic Human Matting》,揭示了阿里巴巴在这方面的数据库和算法设计。

论文称,这是第一个能够完全自动化精细抠图的工作。(其实前几天52CV君介绍了一篇SIGGRAPH2018的论文语义软分割也是类似算法,而且开源了)
下图展示了抠图的应用,计算图像的alpha mate,可以方便将其与其他背景图像合成。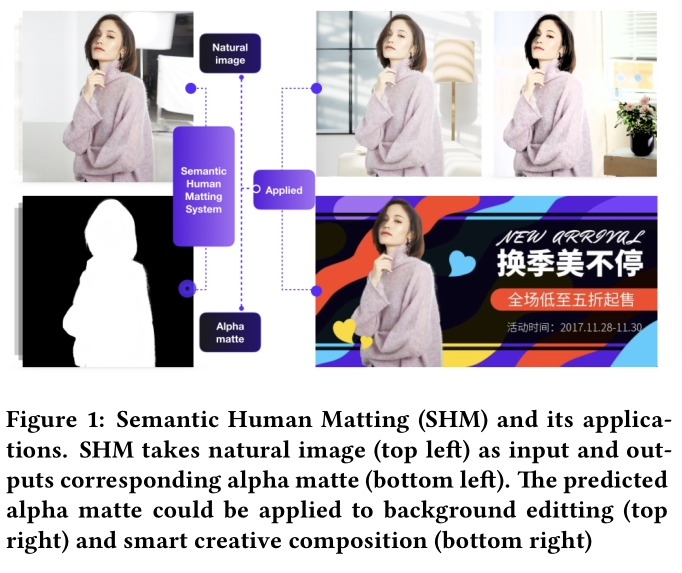
数学上表达这个合成的过程很简单:![]()
F是前景即人物图像,B是背景图像。
数据库制作HUMAN MATTING DATASET
要解决这个问题,首先需要有大规模数据库,学术界研究Matting的数据库往往都很小,难以训练出较满意的结果。
这一步,某宝卖家立大功了!为科研做出了杰出贡献!
论文从某电商平台(嗯,论文中没明说)收集了188K幅由卖家手动抠出来的含有alpha mate的图像,花了1200个小时(50个24小时)从中小心翼翼选择了35311幅高质量含人物的图像,并结合DIM数据集(含有202幅前景图,与自然图像合成20200幅图像),组成了含有52511幅图像的超大规模的Human Matting Dataset。
human matting dataset数据源组成: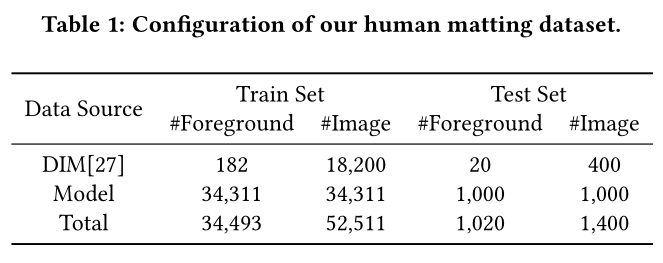
human matting dataset与其他同类数据库的比较: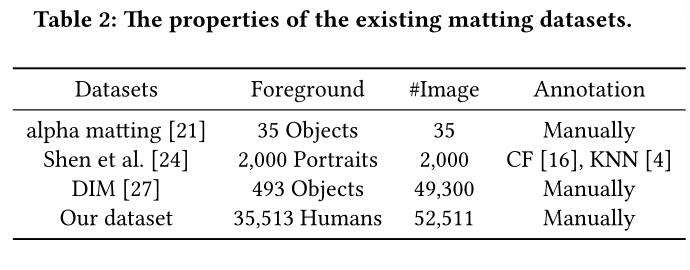
部分数据库中图像示例:

网络架构
该文使用结合语义分割的端到端的深度学习神经网络预测alpha mate。
网络结构如下: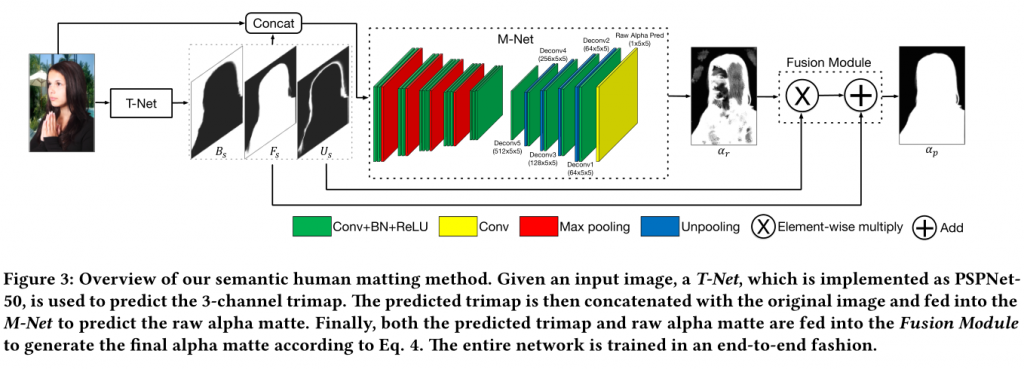
该网络(SHM)主要分为三大部分,T-Net,M-Net,Fusion Module。
T-Net为语义分割模块,使用PSPNet,输入是原始图像,其输出结果是含有前景、背景、未知区域三种类别图像的三色图(trimap)。语义分割是一种粗略的前景提取。
注:在传统Matting的场景中,三色图trimap是由用户手动标注的,可以理解为对图像“完全正确的粗略分割”。
M-Net是细节提取和alpha mate生成网络,使用类VGG16的网络结构,其输入时原始图像和T-Net输出的三色图。
Fusion Module是对T-Net输出的三色图中前景和M-Net输出的alpha mate的加权融合模块,目的是结合语义分割和细节提取进一步提精alpha mate。
网络训练的时候,T-Net和M-Net事先单独预训练,然后整个大网络端到端训练。
实验结果
因为以往算法都需要人工交互得到的三色图trimap来比较matting的性能,而本文算法是完全自动的。为便于比较,作者设计了两个实验。将alpha mate与groundtrut相比较的具体评价标准不再赘述,感兴趣的读者请阅读原论文参考文献21。
1.将T-Net生成的三色图作为传统算法的三色图输入,比较算法生成的alpha mate质量。
结果如下:
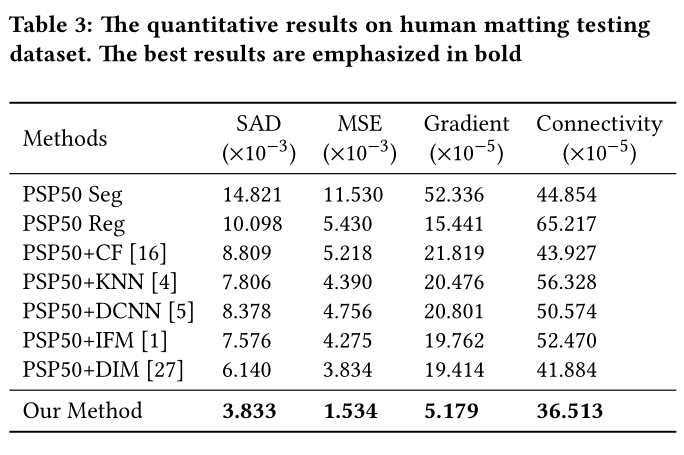
该论文的全自动的SHM算法取得了明显的优势!
2.将手动标注的三色图作为传统算法的三色图输入,比较算法生成的alpha mate质量。
结果如下:
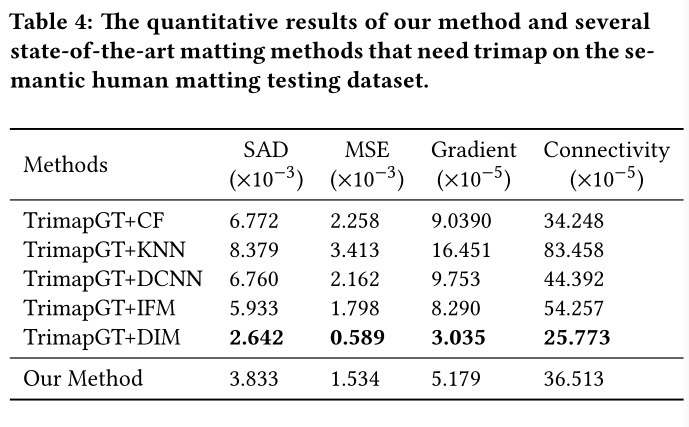
该论文的全自动的SHM算法尽管不是最好的结果,但已经取得了与有人工交互参与的最好结果相匹敌的性能。
下面是算法在测试图像上生成的结果示例图像: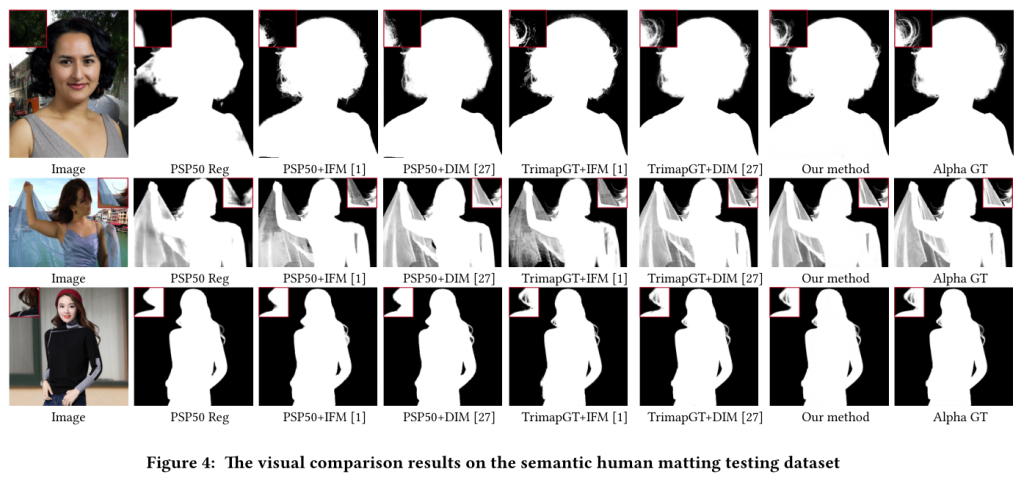
作者然后进一步研究了算法中各部分对性能的影响,发现各部分均有贡献,其中“end-to-end”的训练获得最大的算法性能增益。
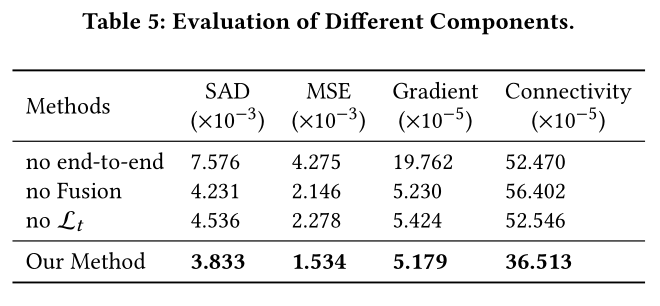
算法各部分输出结果可视化:

a为原图,b为T-Net生成的三色图,c为M-net输出的alpha mate值,d为最终融合模块预测的结果。
下面是SHM算法在实际自然图像中抠像并合成新背景的图像:

52CV君认为自然场景的人物抠图还是蛮有意义的,用在移动视频直播换背景等将大有可为。
这篇论文挺有价值,但更有价值的是某宝卖家给阿里贡献的这个数据集!希望官方能够提供下载就好了。
工程主页:
https://arxiv.org/abs/1809.01354v1


