
商务合作 电话:17719878617
Calamari是一种新的开源OCR识别软件,它使用了最先进的Tensorflow实现的深度神经网络(DNN)。 提供了预训练模型和多模型投票技术。由卷积神经网络(CNNS)和长短时记忆(LSTM)层构成的可定制网络架构通过Graves等人的连接时间分类(CTC)算法进行训练。而GPU的使用大大减少了训练和预测的计算时间。我们使用两个不同的数据集来比较Calamari与OCRopy,OCRopus3和Tesseract 4的性能.Calamari在用现代英语写的UW3数据集上达到0.11%的字符错误率(CER),在用德语写的DTA19数据集上达到0.18% 错误率,其性能远远优于以上现有开源软件的结果。
使用了目前OCR最先进的的技术,CNN+LSTM+CTC+voting。
calamari OCR引擎,使用Python3编写,基于OCRopy和Kraken构建,它的设计使你既可以方便的使用命令行运行,也可以把它模块化嵌入到其他python脚本中。
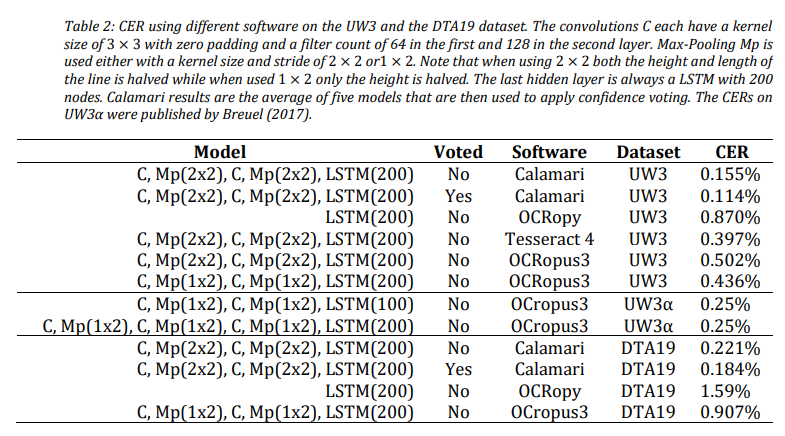
在UW3和DTA19上的识别结果错误率,与OCRopy、Tesseract4、OCropus3相比较:
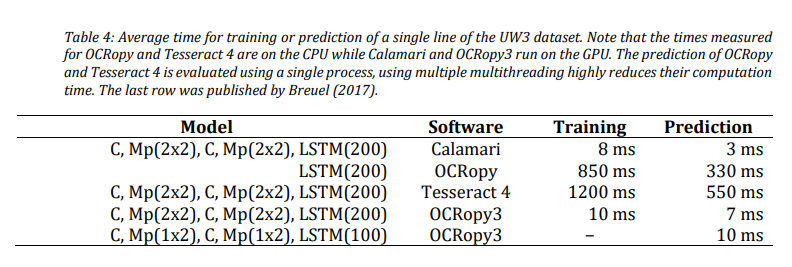
与其他软件相比的识别速度,有GPU加持当然很快:
值得注意的事,该库主要是用来识别印刷体古籍文字,在自然场景图像上的识别并没有实验说明。
文中识别所用的数据库图片示例:

转载来源:《开源OCR文字识别软件Calamari》

