
商务合作 电话:17719878617
来自巴西阿雷格里港大学的学者发表于ECCV2018的论文《License Plate Detection and Recognition in Unconstrained Scenarios》,给出了一整套完整的车牌识别系统设计,着眼于解决在非限定场景有挑战的车牌识别应用,其性能优于目前主流的商业系统,代码已经开源,非常值得参考。
作者信息:
展示了该系统在室外环境,角度变换等场景强大的车牌定位、识别能力。
很多车牌识别论文中常用的数据库往往是正面拍摄的,但实际应用中,各种可能的情况都有,作者首先给出了一些对车牌识别有挑战的数据示例:
该文提出的系统很好的解决了这类有挑战的车牌识别问题。
系统架构
作者提出的车牌识别系统,包含车牌识别的所有环节,主要有三大步骤:车辆检测、车牌检测与校正、OCR。
下图展示了整个系统流程: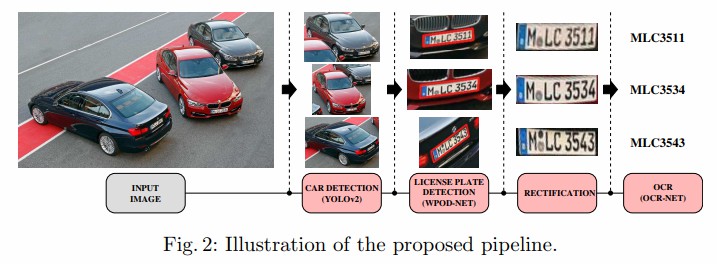
输入图像首先使用YOLOv2进行车辆检测(作者使用原始的YOLOv2,没有做任何改动),检测到的车辆图像再输入到WPOD-NET网络,进行车牌检测和车票卷曲校正系统的回归,然后对车牌进行校正输入到OCR-Net网络,识别出车牌字符。
WPOD-NET用于车牌区域检测于校正系统回归示意图:
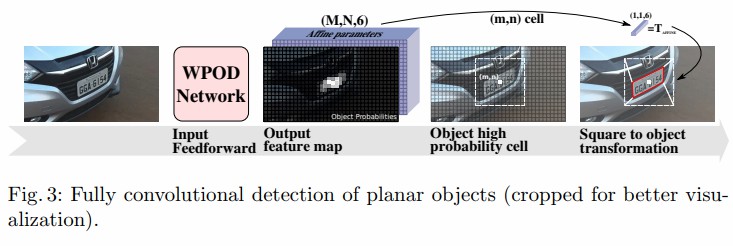
平面目标的全卷积网络检测,对于系统输出的车牌区域特征图,划分成(m,n)个cell,查找高目标概率的cell,根据这些cell的位置,计算将该区域转换成方形车牌的仿射系数。
WPOD-NET架构图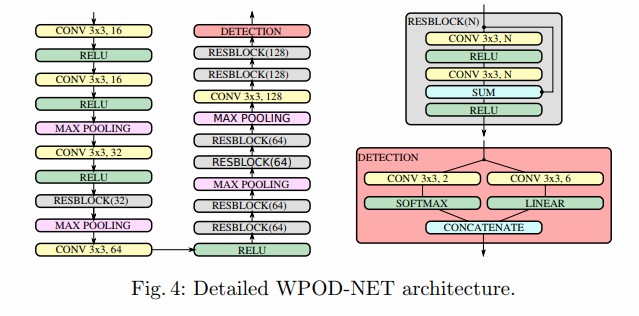
为训练WPOD-NET对数据进行了各种常规的数据增广:

车牌识别OCR部分使用一种改进的YOLO网络,其架构如下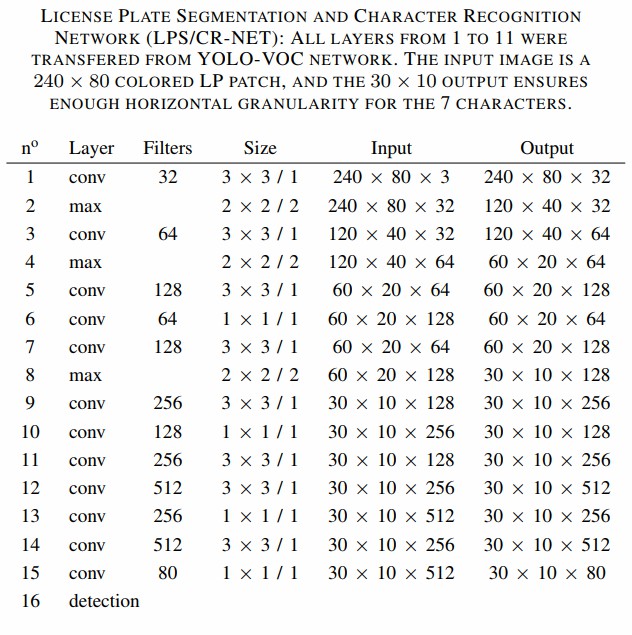
为训练该OCR系统也进行了大量数据增广:

为评估该系统,作者收集了常用的数据集,并自建了挑战的数据集CD-HARD。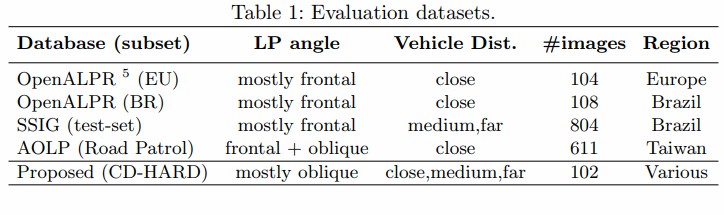
实验结果
作者将该文系统与目前主流的商业车牌识别系统相比较,包括OpenALPR、Sighthound、Amazon Rekognition。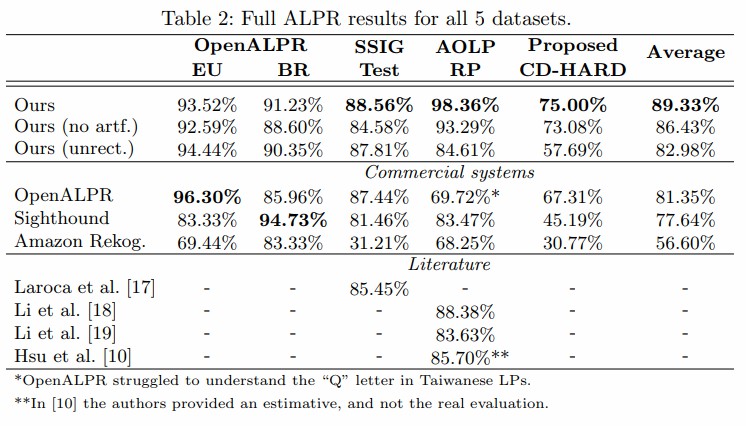
在整个数据集上取得了远超过其他系统的性能,在OpenALPR数据集上取得了与最好系统相匹敌的性能,尤其在具有挑战的CD-HARD数据集上取得了异常明显的性能优势。
一些校正并识别后的车牌示例:

运行速度
在配置为Intel Xeon CPU 、12Gb RAM、 NVIDIA Titan X GPU的机器上,平均达到5fps。
工程主页:
http://www.inf.ufrgs.br/~crjung/alpr-datasets/
https://github.com/sergiomsilva/alpr-unconstrained

