
商务合作 电话:17719878617
昨天,谷歌与霍华德 • 休斯医学研究所 (HHMI) 和剑桥大学合作,发布了一项深入研究果蝇大脑的重磅成果 —— 自动重建整个果蝇的大脑。他们使用数千个谷歌云 TPU,重建的完整果蝇大脑高达 40 万亿像素。有了完整的大脑图像,科学家距离了解大脑如何工作更近了一步。
你知道吗?果蝇是公认被人类研究的最彻底的生物之一,截至目前,已有 8 个诺贝尔奖颁发给使用果蝇的研究,这些研究推动了分子生物学、遗传学和神经科学的发展。
科学家们一直梦想通过绘制完整的大脑神经网络的结构,以了解神经系统是如何工作的。
最近研究的一个主要目标是果蝇的大脑。
果蝇的一个重要优势是它们的大小:果蝇的大脑相对较小,只有10万个神经元,相比之下,老鼠的大脑有1亿个神经元,人类的大脑有1000亿个神经元。
这使得果蝇的大脑更容易作为一个完整的回路来研究。
今天,谷歌与霍华德•休斯医学研究所(HHMI)和剑桥大学合作,发布了一项最新深入研究果蝇大脑的研究成果——自动重建整个果蝇的大脑。

果蝇大脑的自动重建
这篇论文题为“利用Flood-Filling网络和局部调整自动重建连续切片成像的果蝇大脑”:

来自谷歌、霍华德•休斯医学研究所(HHMI)Janelia研究园区以及剑桥大学的一共16位研究人员参与了这个研究,其中,第一作者Peter H. Li是谷歌研究科学家,主要研究方向包括一般科学、机器智能、机器感知。

Peter H. Li
他们还提供了果蝇大脑完整图像的展示,任何人都可以下载查看、或使用交互式工具在线浏览,他们开发了一个3D的交互界面,称为Neuroglancer。
Neuroglancer的演示
这不是果蝇大脑第一次得到完整绘制,今年1月,Science 杂志用封面报道,介绍了 MIT 和霍华德·休斯医学研究所(HHMI)科学家们成功对果蝇的完整大脑进行了成像,并且清晰度达到了纳米级。但那次仍是人工的方法,使用了两种最先进的显微镜技术。

几十年来,神经科学家一直梦想绘制出一幅完整的大脑神经网络的精细地图,但对于拥有1000亿神经网络的人脑,需要处理的数据量之巨大是难以想象的。如果能自动重建果蝇大脑,也许离自动绘制人脑就更近一步了。
这也不是Peter H. Li的团队第一次试图用AI方法绘制大脑神经元,他们分别在2016年和2018年在更小的数据集上进行了研究,如下图右下角所示。

一个40万亿像素的果蝇大脑的3D重建;右下角分别是谷歌AI在2016和2018年分析的较小数据集。
在2018年,谷歌与德国马克斯普朗克神经生物学研究所合作,开发了一种基于深度学习的系统,可以自动映射大脑的神经元。他们对100万立方微米斑胸草雀大脑扫描图像进行了重建。
研究人员称,由于成像的高分辨率,即使只有一立方毫米的脑组织,也可以产生超过 1000TB 的数据。因此,这次重建整个果蝇的大脑,可想数据量有多庞大。
用于处理数据的,是谷歌的Cloud TPU,而且是数千个!
Google AI负责人Jeff Dean也在推特上感叹道:

TPU真的会飞!GoogleAI的科学家使用TPU来帮助重建了整个果蝇大脑的神经连接!
下面,新智元带来对这一研究的详细解读:
40万亿像素果蝇大脑,自动重建!
在实验过程中,主要采用的数据集是FAFB,它是“full adult fly brain”(完整成年果蝇大脑)的缩写(相关数据集信息见文末)。
研究人员在此数据集上,将果蝇的大脑切成了成千上万个40纳米的超薄切片,而后用透射电子显微镜对每个切片进行成像,这就产生了超过40万亿像素的大脑图像。并且将这些2D图像整合成连贯的3D果蝇大脑图像。

接下来,研究人员使用了数千个云TPU,并应用Flood-Filling Network (FFN),以便自动跟踪果蝇大脑中的每个神经元。

通过FFN对整个果蝇大脑进行密集分割(dense segmentation)
上图中的A是3D渲染的FAFB数据集平滑组织掩膜(smoothed tissue mask)。任意冠状切片(数据集XY平面)显示了整个内部的FAFB-FFN1分割。B-E展示了增加缩放比例后的效果。
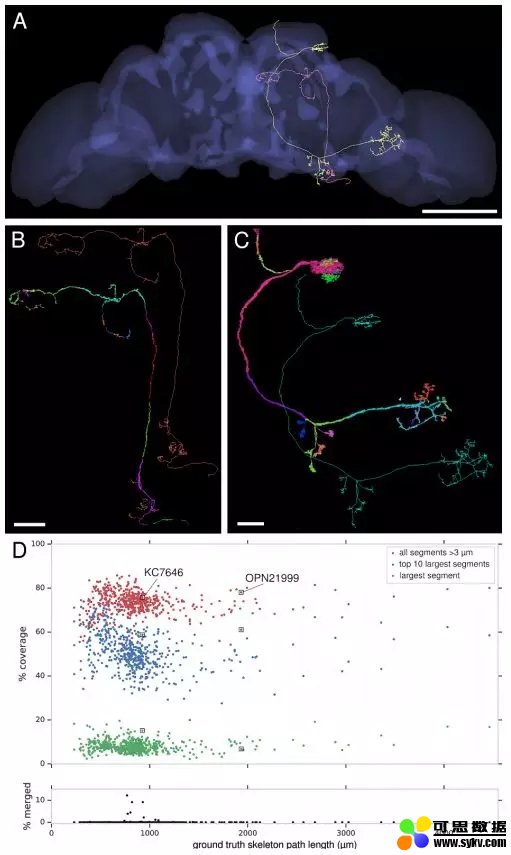
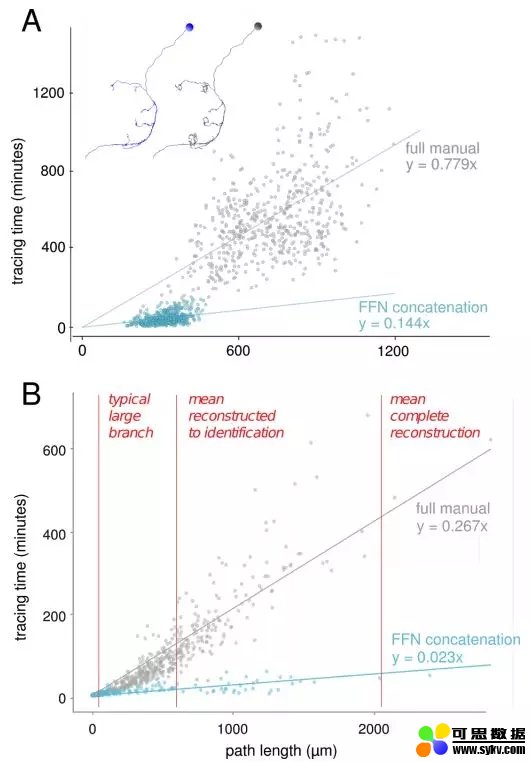
自动神经元重建与手动神经元跟踪做验证对比
虽然这个算法总体运行效果还算不错,但是当对齐(alignment)不够完美(连续切片中的图像内容不稳定)或者偶尔由于在成像过程中丢失了多个连续切片时,性能会有所下降。
为了弥补这个这个问题,研究人员便将FFN与两个新程序结合起来。
首先,估计出3D图像中各个区域切片之间的一致性,然后在FFN跟踪每个神经元的时候局部稳定图像中的内容。
其次,研究人员使用SECGAN来计算图像体积(volume)中缺失的切片,而当使用SECGAN时,研究人员发现FFN能够更可靠地跟踪多个缺失切片的位置。
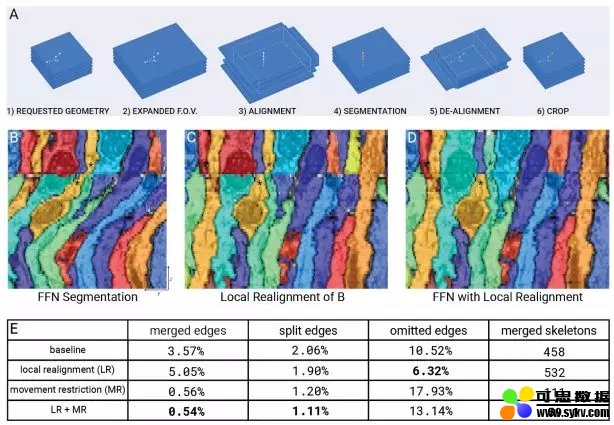
局部调整(Local Realignment,LR)
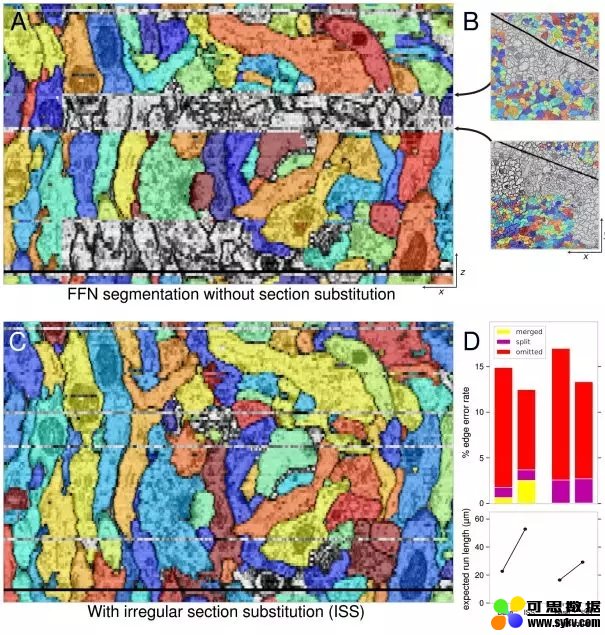
不规则截面的替换
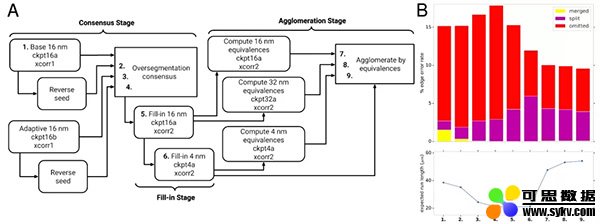
整体FAFB-FFN1的分割pipeline
Segmentation-assisted神经元跟踪
果蝇大脑与Neuroglancer的交互可视化
当处理包含数万亿像素和形状复杂的物体的3D图像时,可视化既重要又困难。受谷歌开发新可视化技术的历史启发,研究人员设计了一种可扩展且功能强大的新工具,任何拥有支持WebGL的网页浏览器的人都可以访问。
结果就是Neuroglancer,一个在github上的开源项目,可以查看petabyte级3D volume,并支持许多高级功能,如任意轴横截面重构(arbitrary-axis cross-sectional reslicing),多分辨率网格,以及通过与Python集成开发自定义分析workflow的强大功能。该工具已被合作者广泛使用,包括艾伦脑科学研究所、哈佛大学、HHMI、马克斯普朗克研究所(Max Planck Institute)、MIT、普林斯顿大学等。



未来工作
谷歌表示,HHMI和剑桥大学的合作者已经开始使用这种重建来加速他们对果蝇大脑学习、记忆和感知的研究。然而,由于建立连接组需要识别synapses,因此上述结果还不是真正的connectome。他们正与Janelia Research Campus 的FlyEM团队密切合作,利用“ FIB-SEM ”技术获得的图像,创建一个高度验证且详尽的果蝇大脑的connectome。

