
商务合作 电话:17719878617
自江森自控(Johnson Controls Inc.)的软件工程师Aditya Vora分享了一种快速精准的人头检测(head detector)算法并开源了代码。
看起来还是不错的!
人头检测在视频监控中非常重要,而公交车、商场或者大型场馆的拥挤人群计数则是其重要应用场景。
算法思想
作者称拥挤人群计数目前主要有两种实现路径:
1.使用回归的算法思路,直接根据图像回归出拥挤人群密度热图,它的缺点是只能得到场景整体的一个拥挤指数,不能获知人群个体的具体位置,而且这种方法对图像分辨率很敏感。
2.使用目标检测的方法,比如直接使用Faster RCNN检测人,检测后数目标为“人”的个数。这种方法的缺点是在人物相互遮挡的情况下往往性能较差,而人群越拥挤相互遮挡的可能性越大,导致算法使用受限。
该文作者希望设计更有针对性的精准的人头检测,实现更加精准的人群计数。
作者创新的两点,轻量级人头检测网络和anchors尺度的选择。
网络架构: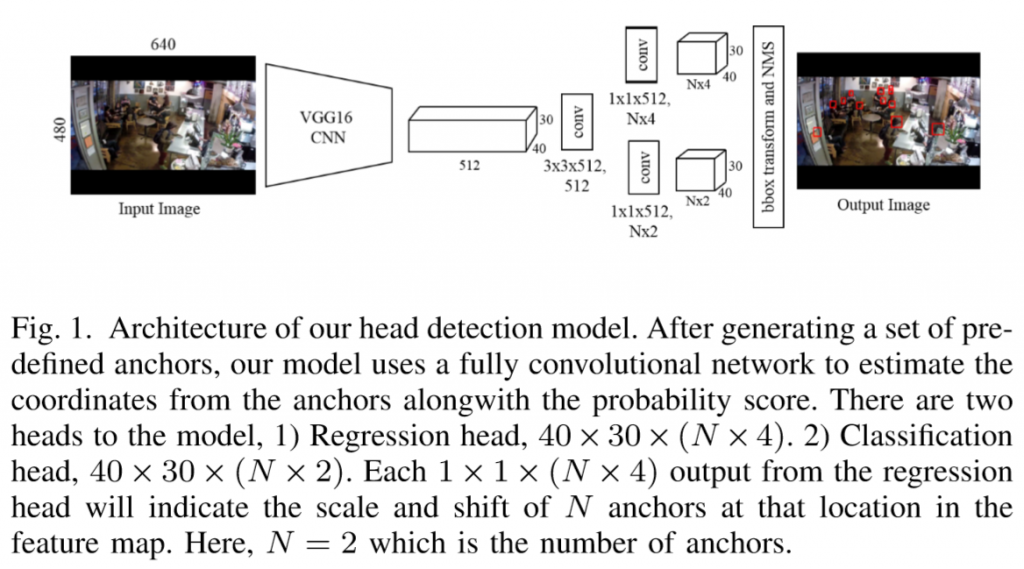
从上图可知,网络的前半部分是VGG16特征提取网络,经过一次卷积,然后分开分别使用1*1卷积进入Regression head(用于回归人头的位置信息)和Classification head(用于分类是否为人头)。
在检测网络中,anchors是很重要的概念,是一组预定义的包围框,在对象检测系统中预测尺度和位移。作者认为普通目标识别中anchors的尺度定义过大,应该根据“有效感受野”(effective receptive field)的思想,减小尺度(直观上“人头”目标比“人体”目标也要小)。
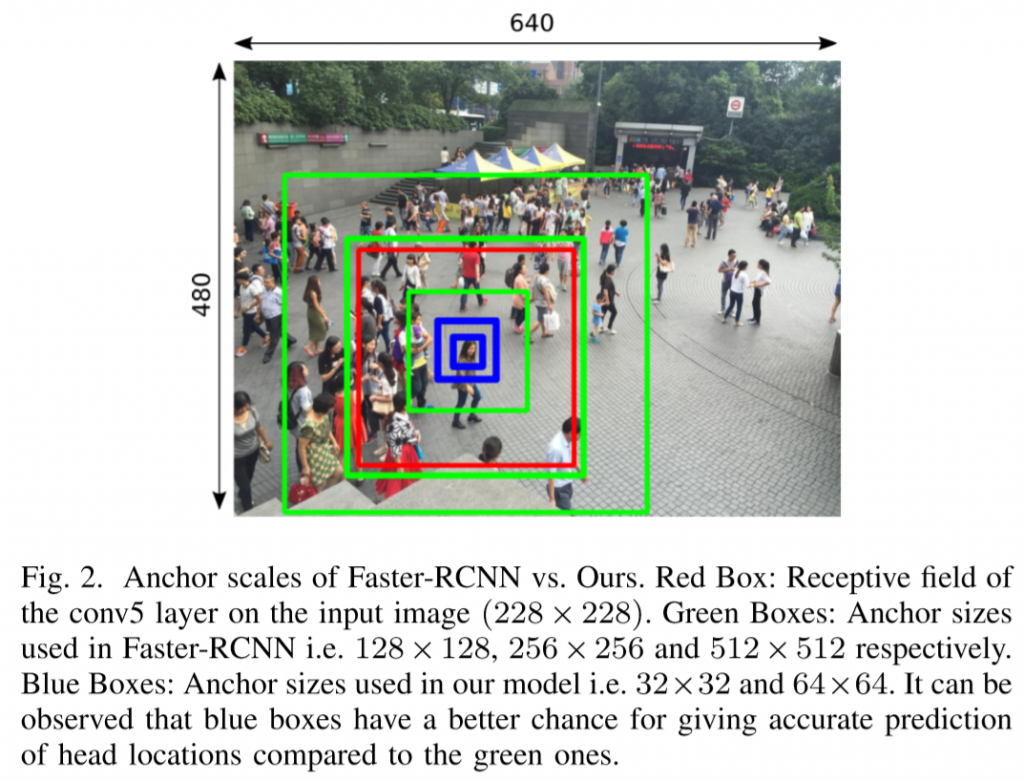
实验结果
作者在BRAINWASH数据库上做了实验,打败了三个基线算法,并取得了与最好结果算法“可比较“的性能。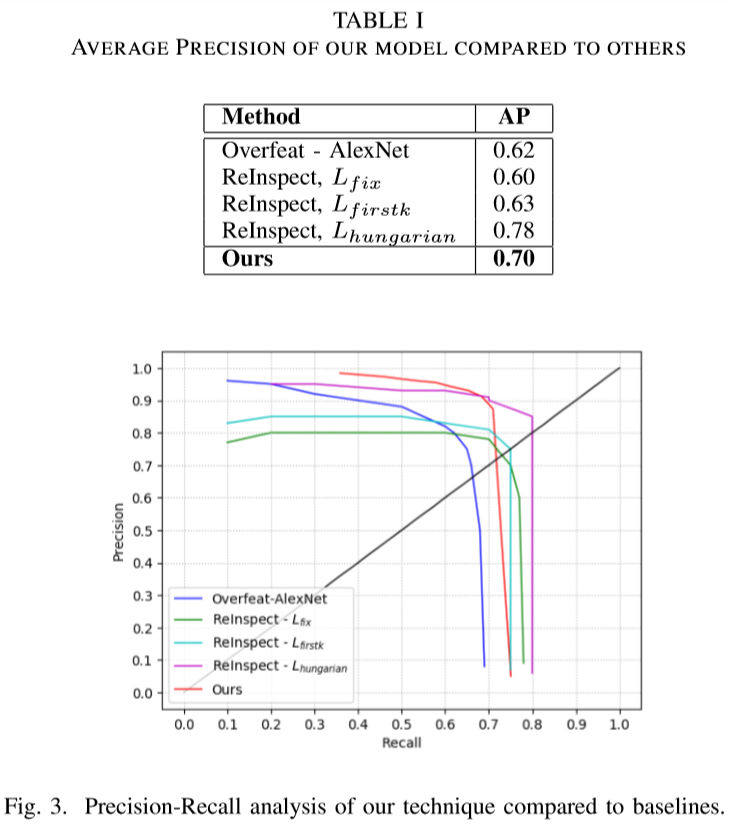
提出的算法比较快,使用Quadro M1000M显卡(仅有512 CUDA核心)速度达到5fps,使用Jetson TX2(仅有256 CUDA核心)速度1.6fps。相比以往算法更加适合于嵌入式边缘计算平台。
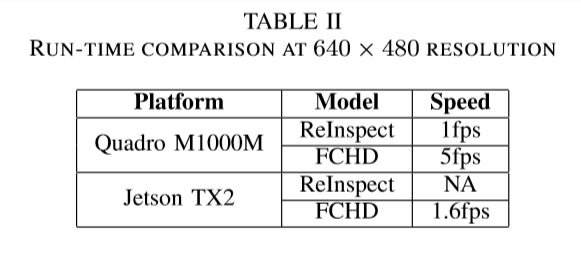
论文地址:
https://arxiv.org/abs/1809.08766v1
代码地址:
https://github.com/aditya-vora/FCHD-Fully-Convolutional-Head-Detector

