
商务合作 电话:17719878617

大数据领域经历了2013年开始的疯狂增长,2016年的断崖式下降,以及2018年以来的迭代复苏,单一的数据技术逐步与人工智能技术结合,应用场景从营销获客、金融风控等为主,转为与城市管理、工业制造等领域越来越深度的结合。大数据产业已进入2.0时代。新时代下,数据与智能融合,新赛道的投资机会如何判断?
中国计算机学会(CCF)大数据专家委员会,每年年底都会发布下一年的大数据发展十大趋势预测。回顾从2013年到2019年的第一大预测,可以发现有意思的发展轨迹:数据的资源化(2013)、大数据从“概念”走向“价值”(2014)、大数据分析成为数据价值化的热点(2015)、可视化推动大数据平民化(2016)、机器学习继续成智能分析核心技术(2017)、机器学习继续成大数据智能分析的核心技术(2018)、数据科学与人工智能的结合越来越紧密(2019)。
从大数据的概念兴起到寻找和挖掘大数据的价值,再到大数据的平民化以及大数据与人工智能的紧密结合,这是一个螺旋上升的过程。在这个过程中,整个大数据产业越来越认同:数据本身没有价值,经过清洗之后才能形成信息,信息只有经过整理才会形成知识,知识只有应用了才会形成智慧,智慧经过收集又变成数据,这是一个完整的循环。
数据经过迭代和循环之后,基于场景化的应用才能创造价值,这已经成为产业共识。进入2018年,我们正处于大数据产业第一轮上升周期的最后阶段——智能应用阶段。现在,各种各样的IT公司、AI公司、大数据公司甚至是SI系统集成商等都在进入所谓“数据智能”领域,造成竞争非常激烈,使得很多从业者在审视方向和战略路径的时候产生了焦虑。其他赛道的争相融合,也使得数据智能赛道中的选手排名有很大的不确定性,再加上这些选手在一级市场高估值的现象,使得投资人在做判断的时候比较纠结。
在2018年12月举办的钛资本“新一代企业级科技投资人投研社”在线研讨会第八期上,达晨财智业务合伙人窦勇分享了对数据智能产业的思考。窦勇在达晨财智负责大数据业务,同时也是中国首席数据官联盟专家组成员,其投资案例包括数联铭品、数据堂、昆仑数据、美林数据、蝎子网络、中奥科技、索为高科、锐思环保等。
走进数据2.0时代

大数据,通俗的讲就是一台机器干不完的事情,利用多台机器来完成。大数据能够快速发展的根本原因无非两个,一个是计算性能的提升,第二个存储成本的降低。
对标国外来看,整个20世纪90年代之前,因为信息化尚未完成,数据量比较少。进入21世纪,移动互联网的兴起使得数据量飙升。2005年,雅虎解决网页搜索问题的时候,提出来两个概念——高性能计算、分布式存储,对行业有着很深远的意义。资本市场更关注的是2009年Splank的上市,来自资本市场的刺激让整个市场为之动容。而2014年Plantir的估值达到200亿美金,更是让国内的整个投资界为之疯狂。
国内来看,从2013年到2017年12月9号,属于数据1.0时代,是进行认知、培训、泡沫、创新的过程。为什么以2017年12月9号为分界点呢?因为在这一天梅宏院士向中央递交了一个报告,从此整个行业进入了数据2.0时代,也就是数据场景化应用、深度融合的时代。
云计算、大数据、人工智能这三者之间你中有我、我中有你、互利共存,一起促进了整个数据智能产业的发展。云计算的出现带动了大数据的热潮,后来人工智能变得更热了,是不是大数据就变得不重要了?其实大数据已经融入到了整个人工智能产业中。
回顾数据1.0时代的投资逻辑
数据1.0时代是一个体现数据差异化的时代,这个时代从消费领域的大数据开始,经历了机器大数据以及后来的工业大数据。
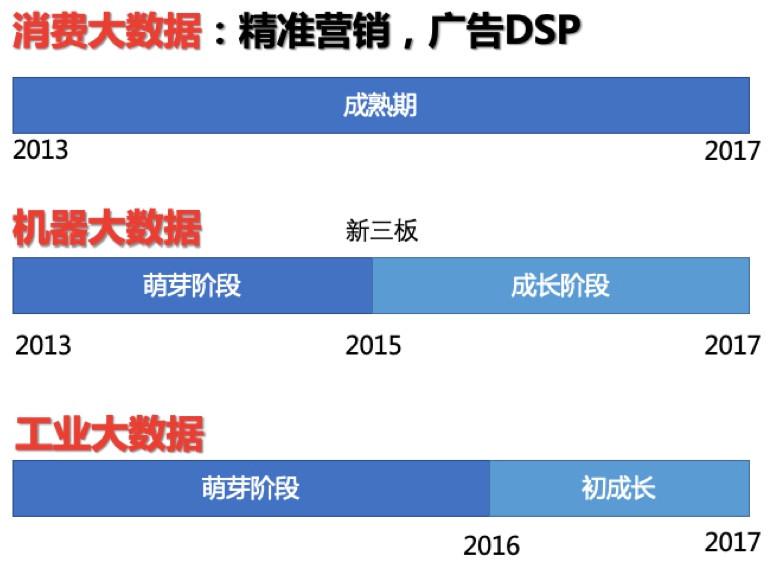
机器大数据萌芽阶段是从2013年到2015年,从2015年进入成长阶段,新三板的介入助推了这个进程。在2016年之前,工业大数据没有得到太多的关注,整个产业现在也还处于发展的初期,这是因为工业领域的信息化尚未完成,有很多的不确定性因素,也存在大量机会。数据1.0时代,从产业角度来看,数据格式从结构化、半结构化、异构化等多样化的融合使得数据源变得更加丰富;而处理数据的手段,无论是基于Hadoop还是Spark的计算方式,都使得整个产业不断地迭代和演进。
数据1.0时代的创业者无非有三类:第一类是原来的传统IT和系统集成商,这一部分群体的出现主要是因为在2015年整个数据行业处于高速发展中,在一级市场给出高估值的情况下,大部分IT系统集成厂商摇身一变成了所谓的数据厂商,他们胜在更贴近用户,但可能对于行业的认知不足,不太关注研发投入;第二类是拥有稀缺数据资源的厂商,他们凭着独有的数据资源能够带来独有的视角和商业价值;第三类是具备技术的创业团队,他们大部分来自于传统的企业IT公司,包括微软、IBM、Oracle等大型厂商,对于技术的应用比较强。在过去五年当中,这三者各有一席之地,但是最终在进入数据2.0时代的时候逐渐融合,都在往场景落地上走,也就是所谓的数据融合。
数据1.0时代从资本的角度来看,2014年Palantir获得200亿美金的估值,加快了国内整个行业泡沫的形成。新三板2015年的推出导致整个行业的虚高。2016年6月1号,《网络安全法》的公布又矫枉过正。特别是对个人隐私数据的极端关注,导致大量行业从业者退出。
而因为泡沫的存在,造成了大量黑产数据的形成,产业里面形成了大量的灰色地带。整个行业陷入极其消沉期是在2017年,由于对整个行业的未来方向都看不清楚,很多人到处尝试,数据行业投入的壁垒也在逐渐加大。
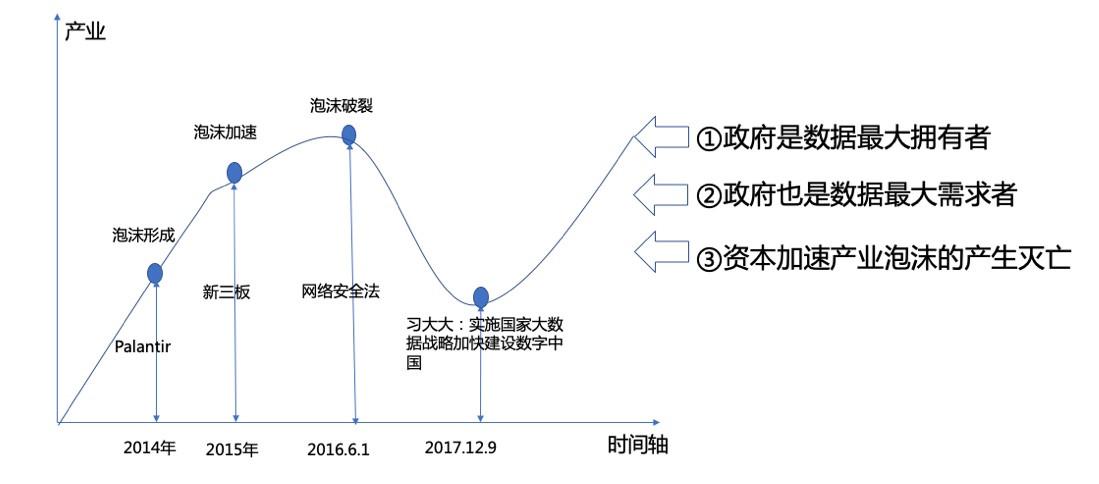
2017年12月9日的“实施国家大数据战略”,为整个数据行业带来了一个新的方向。中国政府是数据最大的拥有者,也是数据最大的需求者,但本身没有技术能力使用数据。因此,如果没有政策的指引,地×××府也不敢投入。所以,2017年12月9日之后,整个行业迎来了快速发展。
对于数据应用来说,什么样的行业领域才能体现数据价值?一是这个行业具备一定的信息化程度;二是具备购买数据服务的能力;三是具有数据安全或安全数据,数据安全是指数据资产本身从流通到应用过程中的安全,安全数据是指数据来源的合法性,对这个问题必须慎之又慎。
对大数据企业进行估值也比较挑战,传统的估值模型往往在现实中不成立。数据企业具有一个显著的特点:除了轻资产外,其它的什么都没有。对于这类型资产怎么进行估值?投资机构在最开始做数据企业估值的时候肯定是“两眼一抹黑”,不过可以基于三个方面的目的进行判断:第一,投资机构确实想进入这个市场,所以在有标的物的估值方面可能会采取折中的办法;第二,投资以退出为目的,估值取决于需要多长时间能够收回本金;第三,数据企业的产品应用场景在哪里,用户的反馈是什么。
还有一些比较实用的小技巧:第一,数据企业到底能解决什么样的问题,是否具备可复制性,持续能力在哪里;第二,团队的构成是否互补,数据企业往往都是科学家型,在面对市场时有哪些短板,如果后期补齐了短板,成长的能力又在哪里;第三,创业早期可能对财务指标不会太在意,但是对于资金的使用去向要特别关注。
数据2.0时代:场景逻辑,巨头形成
数据2.0时代到底是什么样的呢?
从产业内部来看:第一,普适性的教育已经初步完成,分工明确、需求也十分确定,给整个数据产业带来了一个快速发展的强周期,具备了天时、地利和人和;第二,随着金融资本市场进一步的回落,对于数据企业的认知更加回归本质,资本市场给整个产业带来的泡沫逐渐消亡,原来单纯靠PPT演讲就能融资的情况已经基本不存在了。
从产业外部来看:第一,资本市场回归理性,泡沫空间变小。都知道2018年难熬,大家的口号都是“活下去”;第二,外部政策环境持续利好,无论是科创板的即将开板,还是国家把数据行业定位为新经济的重要支柱,都给数据产业的良性发展提供了一个良好的外部环境。
天时、地利、人和都具备了,可以预测,大数据企业在未来的一段时间将形成以下三个良性发展:
第一:场景落地的效应更加明确。到底是针对什么样的场景解决什么样的问题,这种场景是否具备可复制性,持续效应在哪里,如何随着时间的推移得到进一步的应用;
第二,数据龙头企业形成。资本寒冬后留下来的是良品,大数据企业会趋于一种寡头效应。凭借着资本市场以及行业里大量的沉淀,将形成对整个产业的新认知。现在二级市场上虽然很多自称大数据企业,其实真正的大数据企业可能寥寥无几,可以期待之后真正的数据巨头形成;
第三个是技术更新加快。现在无论是从硬件还是软件,整个产业层面对于数据行业的支撑在不断的加快演进与迭变。无论是从计算性能还是存储效率来看,计算效率的极大提升将驱动产业进一步良性的发展。
回归到本质来看,数据2.0时代的“场景落地”到底指的是什么样的场景?这个场景一定是在信息化基本完成的行业里,并且行业具有较强的支付能力。创业公司也不再是项目型,而是以产品的形式带动整个产业的发展。
工业互联网:数据2.0的典型场景
在场景落地方面,工业互联网是一个典型的细分赛道。2017年12月9号之后,最让整个产业界兴奋的事件,就是工业富联上市。工业互联网赛道在当前的寒冬期仍相当红火,主要推手有两个:一个是工信部信通院在推广工业互联网板块,另一个是国家层面的“中国制造2025”。这两个推手促成了工业互联网赛道的趋之若鹜。
但目前我国的工业尚处于3.0阶段,难以跟以高科技著称的美国工业互联网、以机械著称的德国工业互联网对标,所以国家提出了“中国制造2025”。虽然这只是纲领性的文件,但是对整个产业界、投资界以及工业互联网创业圈的振动却不小。
从“中国制造2025”的宏伟目标看,其中的产业机会达上万亿。但整个赛道从投资者的角度来看,创业者并不多。因为既懂IT又懂工业的人少之又少,整个工业互联网赛道看似有巨大的商业机会,但从基本面来看还处于一个比较落后的阶段。
投资人应该怎么看工业互联网?工业互联网可以分两部分:第一,透明工厂,就是在工厂内部围绕产品打通原料、生产流、信息流、资金流,实现设备智能化、流程信息化、过程网络化;第二,以前当产品离开工厂后就很难再与工厂发生联系,而从工业互联角度考虑就要以用户为中心,实现需求个性化、体验场景化、用户生态化。围绕这两部分,工业互联网的体系,从产品全周期管理开始到最终用户互联互通,形成了一个生态。生态当中流通的是数据,以数据的方式驱动整个产业的布局。
按三个层级划分,工业互联网领域可以布局的赛道具体有以下这些:
第一,边缘层。围绕工业互联网的数据汇聚基础,值得布局的赛道有工业传感器、5G、芯片产业。实际上,传感器领域还是被国外厂商垄断,5G核心芯片也是类似情况。但是,随着带宽的提高,采集数据的成本降低了。物联网领域,形成了M2P(Machine-to-Person机器与人连接)和M2M(Machine-to-Machine机器与机器连接),数据的流通得到了进一步的加强。当然芯片不是靠钱能堆出来,但是基于工业互联网的单片机相对比较容易,投入资金也能促成一些基于行业场景化、定制化的芯片,所以这个领域还是有一定的机会。
第二,平台层。可以关注几个方向:首先是行业内的应用平台,这是因为没有行业应用具体特征的数据平台会比较空泛,而解决工业领域各种细分需求的平台需要花费更多时间打造;其次,从技术逻辑角度来看,基于工业产品的时空数据库并没有较好的解决方案,相应可以布局专门针对工业领域数据特点的解决方案。
第三,应用层。因为这个行业相对比较早期,哪怕相对比较大型的企业如树根互联、网智天元、徐工信息等,可能在某一个细分领域凭借原来的行业经验积累了丰富的应用,或者凭借母公司带来相对垄断的资源,但也还都是项目制的方式运营,完全以标准化产品提供服务的还比较少。应用层的创业和投资机会,可以从两个方面考察:第一,信息化是否提前完成;第二,有资金和技改经费。按照这两个标准,能源、电力、高端装备制造业等都是比较好的选择。
整体来说,在工业互联网板块三个层级里,哪一个层级会先有选手跑出来呢?从用户的角度来看,可能是平台层。虽然没有边缘层这些企业解决数据采集、数据治理、数据清洗的问题,平台层无从谈起。但是边缘层往往吃力不讨好。大的企业客户往往急于看到效果,对于平台层的需求往往超出对于边缘层的需求。应用层是不是没有机会呢?也不是。但是在工业互联网领域,用户在意的是究竟能不能解决问题。从行业来看,一定是在能源、电力、高端装备制造业等板块,会较早的跑出一些选手。
大数据领域经历了2013年开始的疯狂增长,2016年的断崖式下降,以及2018年以来的迭代复苏,单一的数据技术逐步与人工智能技术结合,应用场景从营销获客、金融风控等为主,转为与城市管理、工业制造等领域越来越深度的结合。大数据产业正进入到2.0时代。新时代下大数据与人工智能的融合,已然成为各行各业技术驱动、产业升级的重要支撑。具备数据智能的能力、以场景应用为中心的项目,将成为大数据领域的投资主流。

