商务合作 电话:17719878617
百度有一天在某硬件领域成为全球第一,这句话似乎听起来很离奇。如果说这个领域的直接对手,是亚马逊、谷歌、苹果等北美科技巨头,那几乎就更有点神乎其神了。

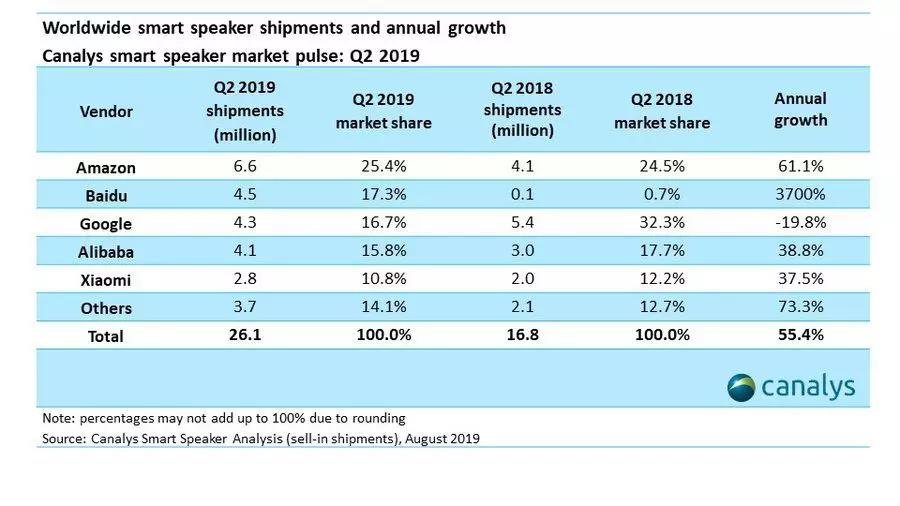
然而根据Canalys最新数据报告,在2019年Q2百度智能音箱出货量继续居于国内市场第一的前提下,已经超过谷歌攀升到了世界第二,前面只有亚马逊最早入场的智能音箱Echo,这个占尽天时地利的对手。
要知道,从小度在家发布至今,百度做音箱仅仅经历了一年半的时间。从初入江湖到中国第一世界第二用了如此短的时间,百度智能音箱产品的全球市场份额,比一年前增长了令人“惊恐”的3700%。只能用惨无人道来形容的增长曲线,似乎正在确立百度硬件领域的生存与发展空间。 而毫无疑问,小度音箱的出货量能否大于亚马逊是一个关键指标,甚至将成为智能音箱发展史的拐点。另一方面,我们知道华为手机在成为世界出货量第一的路上,受到美国以国家力量干扰,至今没有完成。百度能否在音箱之路换道超车,自然也会引发国人强烈关注。 那么“音箱第一大厂”到底能不能换人?答案其实是由三个问题决定的。 路线之问:市场到底想要什么音箱? 用户对小度产品未来的好奇,归根结底在于小度攀升速度过快,大家会奇怪这种急速拉升究竟是一个可保持的长期趋势,还是短时间刺激效应下的虚假繁荣? 换句话说,小度究竟是走在正确的路上,还是仅仅踩了个幸运蘑菇? 这个问题必须交给智能音箱短暂但急促的发展史去回答。亚马逊Echo与谷歌Nest系列之间的关系,颇有点像天猫精灵与小度。只是中国市场相对更复杂,还要加上小米以及众多已经告别历史舞台的音箱产品。 如果说中美两开花,不,是两条线有什么共同特点,就在于“技术流”蚕食“电商流”是个必然趋势。谷歌凭借Assistant不断升级的语音交互能力,以及与安卓生态的关系,在亚马逊已经牢牢占据的智能音箱江山里杀了出来,做到今天北美市场快要分庭抗礼的程度。而国内音箱“三巨头”,小度起步最晚,却通过小度助手背后强大的技术能力,不断分割小米和阿里的市场份额,拓展智能音箱的市场边界。 不难看出,智能音箱落脚市场的关键还是智能技术。声音识别、唤醒、语义理解、多轮对话等能力构成了这个硬件值得被使用的基础。技术体验不流畅,可能直接造成打开率下降,影响市场购买率。这个硬卡位的存在,让电商体系与IoT体系带来的赋能相形见绌。 这个逻辑的最新论据在于,谷歌今年没有拿出什么能够引发极客们热情高涨、用户付出真金白银的技术,而是更多在产品的系列化以及周边设计上下功夫。无论我们将其看作调整周期还是谷歌的技术创新疲软,最终结果就是谷歌挑战亚马逊的步伐减慢,在全球范围内被百度完成了销量反超。 而与小度硬核崛起所同步的,恰好是底层技术创新。在不久前发布并已经搭载到小度音箱产品中的小度助手5.0,唤醒能力上加入了流式截断的多层注意力模型(SMLTA);在语义理解算法层融合了百度NLP的知识增强语义表示模型ERNIE,小度助手的核心理解算法升级为超大数据预训练深度模型,让众多NLP任务都有了新的表现;此外,全双工免唤醒能力的加入,让小度助手5.0有了人类之间对话时的“拒绝反应”,能够一次唤醒多次交互,让音箱主动分辨何时“不说”。 另一个值得注意的技术-产品关键问题,来自于带屏音箱新品类的市场认可。根据Canalys数据报告,在Q2小度全球音箱出货量中,有45%是带屏音箱。可见用户对这一新产品品类已经有了深刻接受度。而Canalys也指出,百度在带屏音箱中近乎于是没有竞争对手的。这条产品路径,正在成为小度的独属红利。 用户对于智能音箱体验的认可和需求,从来就没有降低过。换言之核心技术才是智能音箱的主要矛盾,从美国的谷歌生吃亚马逊,到中国的“千箱-三箱-小度超级箱”之路,都可以佐证市场核心逻辑的所在位置。 那么回到最初的答案,持续保持底层技术创新的百度,与长时间缺乏底层AI技术创新的亚马逊,处在一个努力奔跑,一个缓慢散步的进程里。百度反超,是存在战略上可能性的。 那么从战略到战术,关键问题在哪呢? 大妈之问:中国市场到底有多大? 通过底层技术创新,拉动技能开发生态和内容平台,这样的模式让国内智能音箱市场快速从三强争霸变成了一超两强。在小米和阿里近期无力概念技术和生态格局的条件下,这个局面今天来看应该会一直持续下去。 但是百度能否挑战世界第一的位置,很大程度上并不取决于国内竞争。因为现在中美音箱是你卖你的我卖我的,大家没事不串门。所以销量规模上的比拼,源自于各自市场容量的边界。换句话说,百度到底能把中国市场做到多大,是否能让中国市场音箱保有量超过美国,这个才是问题关键。 毫无疑问,中国市场上的智能音箱,正在享受互联网模式下的人口红利。根据Canalys预测,今年中国内地智能音箱数量将同比增长166%,效率冠绝全球,是美国46%增速的三倍。 这样的市场增速来源是多方面的,首先中国市场智能音箱的性价比依旧重要,这让智能音箱在中国市场基本属于无门槛消费。再者随着小度等音箱不断完善能力和内容,音箱的受众范围得到不断推广,家庭市场、教育市场在不断深化。 但真正决定中国市场销量边界的,其实是下沉市场的打开效率。几个月之前,我采访过烟台农村的一位大姐,她告诉我她家有一台小度在家,两台小度音箱(无屏版)。而这样的配置在她们村并不少见。可以直接对话,调出音乐、内容,以及应用的智能音箱,正在与中国广袤的黄土地毫不违和地沾粘在一起。 在理解智能音箱下沉市场的边界有多大时候,必须正视今天这样几个现状: 1、智能音箱抢占的是谁的市场?在具有长时间内容收听能力的市场里,不是一种音箱打败另一种音箱,而是这种智能交互模式+内容通道,收割收音机、低音炮、电视,甚至手机的存在时间。音箱体验的简便性,会从下沉市场首先发酵。 2、互联网服务增值模式与音箱之间的联系,构成了很多内容、电商、教育可以围绕音箱打开。这些内容在大都市可能很自然通过手机获取,音箱更多属于垂直人群,但在下沉市场,手机性能并不强,反而是便宜的音箱更可能成为入口。因此音箱的人均普及价值可以很快超越手机。 3、下沉市场的增长法则相对明确,大覆盖面广告效果明显。在春晚植入和热播综艺的普及下,如今用户已经对智能音箱产生心理预期和理解能力,市场教育周期已经基本完成。 在这三个条件下,智能音箱的市场边界还远远没有达到顶点。小度贯穿一线城市到乡村的销售覆盖网络,则强化了小度的市场打开通道。 如果继续保持目前的增长速度,小度基于中国市场的穿透力,销量超越亚马逊将不需要太长时间。无论国外媒体感觉多么不可思议,中国大妈说,这事是我们罩的。 苹果之问:去往海外的音箱如何生存? 再向更远处看,中美智能音箱的冠军,必然在世界范围内还有一战。但这场战斗发生在哪大有学问。 事实证明,美国音箱想在中国存活近乎不可能;看川普推特里的小情绪,中国音箱想进美国大概短期也不现实。 到2019年年底,全世界智能音箱预计可以达成2亿台的安装量,其中中国6000万,美国9000万。那么也就是说,全球还有四分之一非中非美市场。 根据Canalys的数据,这些市场份额里,目前对智能音箱接受度最好的是日本和韩国。在Q2这两个市场分别达成了131%和132%的增速,仅次于中国名列二三。 必须注意的是,这两大市场使用的语言既不是英语也不是汉语。所以从AI巨头输入产品解决方案时,这些市场需要的是多轮对话、语义理解、NLP的底层能力。 亚马逊和百度,谁能在这全球四分之一的市场里占领未来呢?这个远距离推测很可能给人不公允的感觉。但不妨来看一下,已经在中国卖了大半年的苹果智能音箱,是怎么失败的。事实上,苹果的HomePod基本可以判断为一款失败的产品,只不过是北美小败其他市场大败而已。4月,苹果不得已宣布HomePod永久降价50美元,可见其失利幅度之大。 苹果的音箱之痛,可以总结为三个问题:智能交互太差,尤其是非英语体验极其不好;昂贵的定价在其他智能音箱玩家面前没有任何竞争力,反而有浓厚的智商税嫌疑;应用体系,内容服务和IoT生态都没有,消费者不知道买来干什么。 苹果的问题,没有哪家企业敢不吸取。于是我们可以看到,音箱出海,脱离了本身市场的知名度和品牌能力之后,真正比拼的是三点:技术能力、定价能力、生态服务。 回到百度和亚马逊未来可能的出海对决中,今天底层技术的创新百度已经领先于业界,语音智能相关的底层算法幅度,更是从今年开始领先了AI老大哥谷歌,这是前所未见的。 而定价能力上,更靠近中国完善产业链的百度,显然不会拿出贵到离谱的产品走向世界。反而因为音箱品类的集成度有效,净值又不高,北美巨头很难在代工模式中发挥手机和平板的成本控制能力,很可能在直接与中国品牌的碰撞中陷入尴尬。 那么最后在生态服务能力上,百度与亚马逊如果真的展开较量,那就将是亚马逊依然强劲的世界电商网络能力,与百度代表的中国互联网服务模式的缠斗。这其中需要发挥中国互联网公司源源不断的运营和服务创新能力,可能要经历一场群狼搏虎的战斗。 虽然这个类比并不意味着真正的未来,但是2比1,是绝对能够说明某种态势的。而且出海之战,百度真正迎战谷歌或者亚马逊的时候,大概率小度已经是全球第一大音箱厂商了。 从无人机,到手机,再到音箱,世界第一并不只是个名号,还是中国科技产业不容放弃的话语权。当百度成为世界音箱一哥的同时,也是下个时代的大门被悄悄推开的时候。