
商务合作 电话:17719878617
说起“改头换面”,恐怕大家都觉得这不是一朝一夕的事儿。
然而就在最近,网友们惊讶的发现,这件事竟能眨眼间搞定了!
94版《射雕》里黄蓉的扮演者突然从朱茵变成了杨幂,服化道画风丝毫都没有变化……

就连表情神态也惟妙惟肖,毫无违和感。

拔群的效果果然引来一众吃瓜群众围观,热搜话题阅读量超过了1.3亿。
这种被称作黑科技的AI换脸,国内也有不少仿效者,比如有网友把女主播的脸换成唐嫣、杨幂、刘亦菲等明星,真是吓傻了小编呢!
Deepfake到底是啥?
网友们在感叹技术高超惊艳的同时,也有些担心了,毕竟这种“移花接木”的功能可不能乱用啊!
这到底是一项怎样的黑科技,国外名人明星又是如何惨遭“换脸”的?
据中国日报网站报道,这项“换脸技术”,名为deepfake,由英文中的deep learning(深度学习)和fake(伪造)两个词合成而来。这是一项基于人工智能(AI)的人物图像合成技术。
视频制作人只要在社交媒体上大量下载替代者与被替代者的静态图片和视频,然后用如TensorFlow等开源软件库进行学习,经过足够多的训练之后,电脑就能自动识别、换脸。
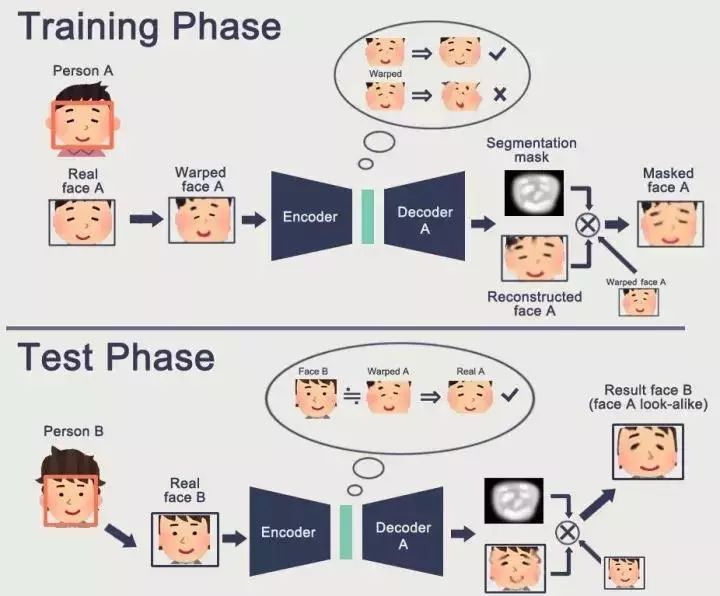
换脸视频大部分由AI软件FakeApp制作而成。在Reddit和Discord网站中这些假视频分享得很火。
制作视频的这款软件需要提交被替换人的大量照片,因此名人和公众人物,比如美国的前总统,都成了轻易被剪辑的对象。
就连奥巴马也没能躲过……(让小编乐一会O(∩_∩)O哈哈~)

点我科技公司的找标注网平台拥有丰富的数据清洗、采集、标注经验,平台还活跃着庞大的数据标注从业团队,为众多优质企业客户提供数据标一体化的服务,为AI+产业落地奠定了坚实的基础。
点我科技可以为企业用户带来高效、高质量的AI数据服务!!!


