商务合作 电话:17719878617
数据标注就是使用自动化的工具从互联网上抓取、收集数据包括文本、图片、语音等等,然后对抓取的数据进行整理与标注。数据标注与审核行业上游为计算机软硬件生产商及人力资源行业,下游主要是安放、自动驾驶等人工智能领域。
数据标注与审核行业产业链示意图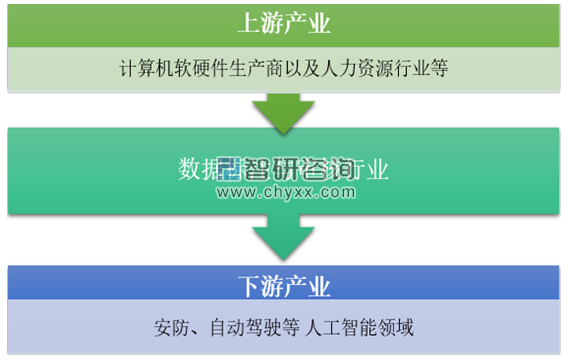
资料来源:智研咨询整理
智研发布的《2019-2025年中国数据标注与审核行业市场专项分析研究及投资前景预测报告》显示:近几年,数据标注与审核行业快速发展,2018年市场规模已达到52.55亿元,至少在未来的5年内,数据标注行业的增长空间还很大,数据标注的市场才刚打开,数据需求将紧随人工智能的大规模落地引来一波爆发式增长。
2015-2018年数据标注与审核行业市场规模及增速情况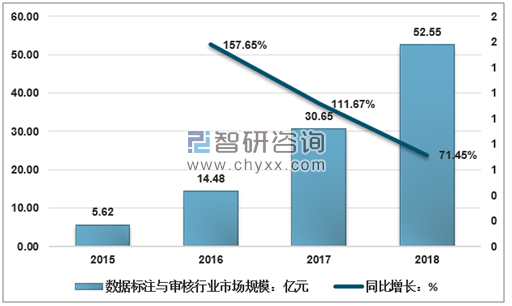
资料来源:智研咨询整理
近几年,随着国内人工智能行业的飞速发展,数据标注与审核行业产值快速增长,从2015年的5.85亿元增长到2018年的54.02亿元,近几年我国数据标注与审核行业产值情况如下图所示:
2015-2018年中国数据标注与审核行业产值情况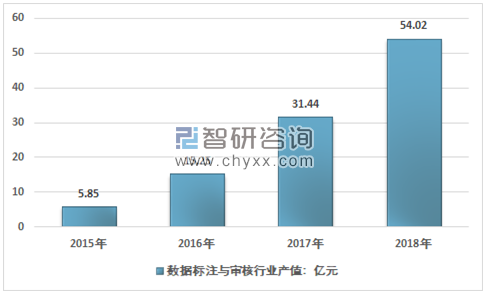
资料来源:智研咨询整理
2018年我国数据标注与审核行业规模达到52.55亿元。其中,有三分之一是AI公司内部的标注部门消化,另外三分之一被商务流程外包公司瓜分,剩下的34%左右业务量流向专门做数据采标的第三方公司。
2018年我国数据标注与审核行业分布格局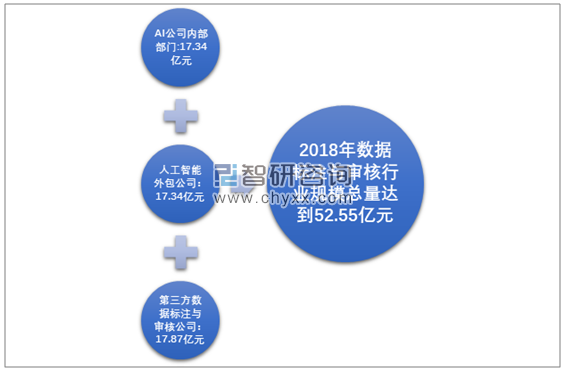
资料来源:智研咨询整理
2018年我国部分地区数据标注与审核行业优势企业一览
产品名称 | 所属公司 | 所在地区 | 简介 |
荟萃 | 上海丁火智能科技有限公司 | 上海(华东) | 丁火智能是一家人工数据标注服务提供商,通过“移动众包执行+全职员工全检”模式,为企业提供数据采集和标注服务,“移动众包”用于降低成本提高效率,“全职员工”用于保证交付数据质量,提供的服务包括图片、文本、语音和视频的采集和标注。 |
龙猫数据 | 北京安捷智合科技有限公司 | 北京(华北) | 龙猫数据是一家专业的人工智能数据服务提供商,致力于提供人工智能大数据采集、数据标注、数据提取、数据校验、数据清洗、线上众包等服务,服务领域涵盖图像、语音、文本、视频四个方面。 |
爱数智慧 | 北京爱数智慧科技有限公司 | 北京(华北) | 爱数智慧——专业的AI人工智能数据服务提供商。致力于提供智能语音、图像、文本数据的采集、清洗、标注、校验等服务,为深度学习提供训练语料。 |
视在科技 | 杭州视在科技有限公司 | 上浙江(华东) | 视在科技是一家基于视觉行为分析的运营服务公司。公司通过VAI技术实现数据自动标注化、结构化等行为算法,将大数据显像化并提供行业解决方案和AI算法,进而形成闭环商业链。 |
泛函科技 | 北京泛函科技有限公司 | 北京(华北) | 泛函科技是一家以技术为核心,专注于各类语音、图像采集及数据处理科技公司,可承接全世界30+类语言语音及图像文件的标注和清洗工作。拥有覆盖全球36个国家和地区的采集和标注资源,致力于为客户提供一站式训练集数据定制服务 |
锦翰科技 | 锦翰科技(深圳)有限公司 | 广东(华南) | 一家位置数据服务提供商,致力于利用地图、定位和大数据分析技术为传统的建筑物运营管理者提供数字化的运营、管理、营销的位置服务解决方案,同时为消费者提供基于位置的崭新服务。 |
BasicFinder平台 | 北京深度搜索科技有限公司 | 北京(华北) | 深度搜索科技是一家图像识别与深度学习技术研发商,公司的主要业务包括提供大数据标注、人工智能技术咨询与提供相应的技术解决方案、智能系统企业定制和智能生活平台化产品等多项服务。 |
星尘数据 | 北京星尘纪元智能科技有限公司 | 北京(华北) | 星尘数据是一家为专为人工智能研发机构服务的数据众包平台。我们提供训练模型过程中所需要的人力来帮助解决数据的采集、标定、质量监控等工作,使企业能够专注于自己的核心业务。星辰数据的团队成员均来自于世界一流的知名企业,有着多年机器学习的经验和对数据标注服务的深入理解。我们结合了谷歌、百度等世界顶尖人工智能公司的标注系统,轻松、快捷地解决您的所需标注任务。 |
霓螺 | 霓螺(宁波)信息技术有限公司 | 浙江(华东) | 霓螺是一家图像视频扫描与识别技术服务企业,包括物体检测,将对上传的视频进行快速扫描探测并识别出人、车、物。推荐视频中NILO标签标注点;图像识别,对物体图像进行搜索,建立视频内标记NILO标签的物体与数据库中信息的关联关系;以及运动跟踪,所有的NILO标签都可以自动跟踪物体的运动轨迹。 |
资料来源:智研咨询整理
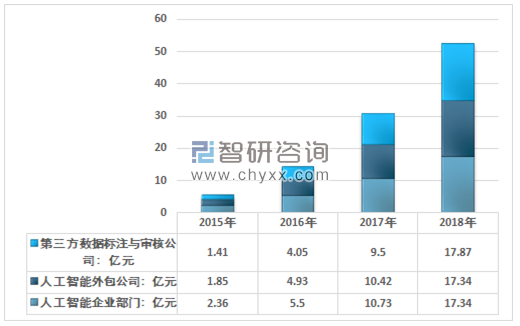
2015年,我国数据标注与审核人工智能企业部门规模为2.36亿元,人工智能外包公司规模为1.85亿元,第三方数据标注与审核公司规模为1.41亿元。2018年,我国数据标注与审核人工智能企业部门规模为17.34亿元,较上一年相比增长了61.60%,人工智能外包公司规模为17.34亿元,较上一年相比增长了66.41%,第三方数据标注与审核公司规模为17.87亿元,较上一年相比增长了88.11%。
2015-2018年中国数据标注与审核应用市场需求特征