商务合作 电话:17719878617
为什么3D点云数据在人工智能自动驾驶领域需求越来越大
1)硬件设备采集性能更好了:
随着3D采集技术的快速发展,3D传感器越来越多且价格实惠,自动驾驶汽车搭载的传感系统已经包括各种类型的3D扫描仪、激光雷达和RGB-D摄像机(如Kinect、RealSense和RealSense、苹果深度相机)来进行周围环境的感知。
2)3D数据可以提供更多的维度信息
这些传感器获取的3D数据可以提供丰富的几何、形状和比例信息;与二维图像相辅相成,三维数据提供了一个以更好地了解机器周围的环境的机会。三维数据通常可以用不同的格式来表示。包括深度图像、点云、网格和体积网格。作为一种常用的格式,点云保留了原始的几何信息在三维空间中,不需要任何离散化。因此,它是许多场景理解相关的首选表示方法。
3)深度学习技术可以处理无序的3D数据的方法越来越多
深度学习作为人工智能领域的主要技术,深度学习已经成功用于解决各种二维视觉问题。然而,由于通过深度神经网络处理点云的过程中面临的独特挑战,点云上的深度学习仍处于起步阶段。近来,点云上的深度学习更加蓬勃发展,众多的方法正在提出解决这一领域的不同问题。
点云上的深度学习一直吸引着更多的和更多的关注,特别是在过去五年。一些公开的数据集也被发布,如ModelNet , ScanObjectNN , ShapeNet , PartNet ,S3DIS , ScanNet , Semantic3D , ApolloCar3D, and the KITTI Vision Benchmark Suite 。这些数据集进一步推动了深度学习在三维点云上的研究。随着越来越多的方法拟解决与点云处理有关的各种问题,包括3D形状分类、3D物体检测和跟踪、3D点云分割、3D点云对准、6-DOF姿态估计和3D重建,有关于三维数据的深度学习的调查研究越来越的发布。
3D点云数据在自动驾驶中的优势有什么优势?
在人工智能自动驾驶领域中,准确的环境感知和精确的定位是自动驾驶汽车在复杂动态环境中能够进行可靠导航,信息决策以及安全驾驶的关键。这两个任务需要获取和处理真实环境中的高度准确且信息丰富的数据。为了获得此类数据,无人车上或者移动测量车上通常装备多种传感器,例如LiDAR或者相机。传统上,相机捕获的图像数据能够提供二维语义和纹理信息,且低成本和高效率,是感知任务中最常用的数据之一。但是,图像数据缺少三维地理信息。因此,由LiDAR收集的密集的、准确的、具有三维地理信息的点云数据也应用于感知任务中。此外,LiDAR对照明条件的变化不敏感,可以在白天和夜晚工作,即使有强光和阴影干扰,是3D点云数据的优势。
3D点云在自动驾驶领域中的应用可以分为以下两个方面:
基于场景理解和目标检测的实时环境感知和处理;
基于可靠定位和参考的高精度地图和城市模型的生成和构建。这些应用具有一些类似的任务,可以大致分为三种类型:点云分割,三维目标检测和定位以及三维目标分类和识别。这项技术的发展引发了自动驾驶领域对3D点云数据自动处理与分析的日益迫切的需求。
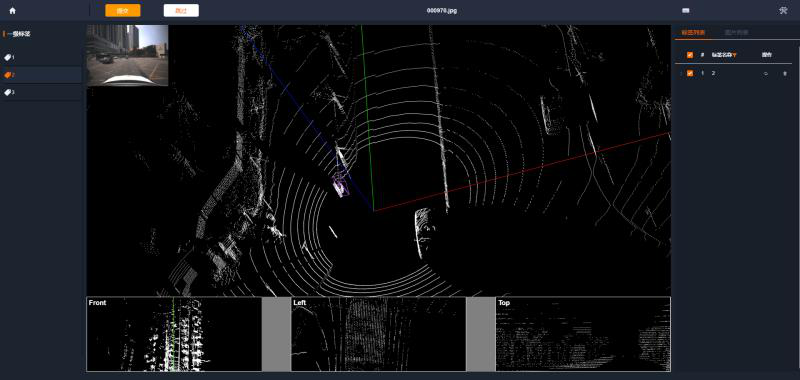
有哪些可以用的3D点云 数据标注工具?
当下对3D点云数据的需求越来越大,需要更加好用的3D点云数据标注工具对数据进行快速标注,整理了几个3D点云的数据标注工具,国外有 PCAT_Open_Source, Semantic-Segmentation-Editor等,国内有很多标注平台均有自己的3D点云标注工具,但是并未对外开放使用,觉醒向量开发的LabelHub在线标注工具平台,即将开放3D点云标注工具,欢迎关注并体验。