商务合作 电话:17719878617
人工智能(AI)问世之初曾经狂妄自大、令人失望,它如何突然变成当今最热门的技术领域?人工智能(AI)问世之初曾经狂妄自大、令人失望,它如何突然变成当今最热门的技术领域?
这个词语首次出现在1956年的一份研究计划书中。
该计划书写道:“只要精心挑选一群科学家,让他们一起研究一个夏天,就可以取得重大进展,使机器能够解决目前只有人类才能解决的那些问题。”
至少可以说,这种看法过于乐观。
尽管偶有进步,但AI在人们心目中成为了言过其实的代名词,以至于研究人员基本上避免使用这个词语,宁愿用“专家系统”或者“神经网络”代替。
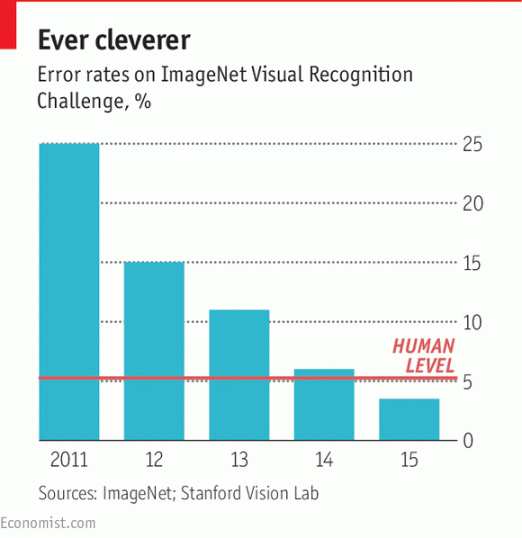
“AI”的平反和当前的热潮可追溯到2012年的ImageNet Challenge在线竞赛。
ImageNet是一个在线数据库,包含数百万张图片,全部由人工标记。每年一度的ImageNet Challenge竞赛旨在鼓励该领域的研究人员比拼和衡量他们在计算机自动识别和标记图像方面的进展。
他们的系统首先使用一组被正确标记的图像进行训练,然后接受挑战,标记之前从未见过的测试图像。在随后的研讨会上,获胜者分享和讨论他们的技术。
杰夫里·辛顿(Geoffery Hinton)
2010年,获胜的那个系统标记图像的准确率为72%(人类平均为95%)。2012年,多伦多大学教授杰夫·辛顿(Geoffery Hinton)领导的一支团队凭借一项名为“深度学习”的新技术大幅提高了准确率,达到85%。后来在2015年的ImageNet Challenge竞赛中,这项技术使准确率进一步提升至96%,首次超越人类。
2012年的比赛结果被恰如其分地视为一次突破,但蒙特利尔大学计算机科学家约书亚·本吉奥(Yoshua Bengio)说,这依赖于“将之前已有的技术结合起来”。
约书亚·本吉奥(Yoshua Bengio)
本吉奥和辛顿等人被视为深度学习的先驱。
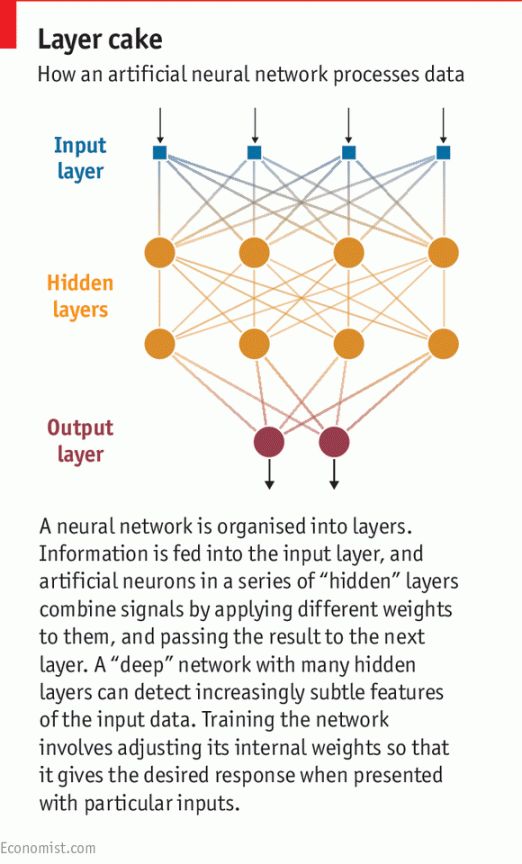
从本质上来讲,这项技术通过强大的计算能力和大量的训练数据,复兴了AI问世之初的一个旧想法,也就是所谓的人工神经网络(ANN),其灵感来自于大脑神经元网络。
在生物大脑中,每个神经元被其他神经元发来的信号触发,其自身发出的信号又会触发其他神经元。一个简单的ANN包含一个向网络输入数据的神经元输入层,和一个输出结果的输出层,也许还有两三个处理信息的中间隐藏层(实际上,ANN完全由软件模拟而成)。
网络中的每个神经元都有一组“权值”和一个控制其输出启动的“激活功能”。神经网络的训练涉及到调整神经元的权值,使特定的输入产生我们需要的输出。上世纪90年代初,ANN开始取得某些有用的结果,比如识别手写数字。但如果让它们去做更加复杂的任务,就会遇到麻烦。
在过去十年里,新技术和对激活功能的一个简单调整使训练深度网络成为可能。同时,互联网的崛起使无数的文档、图片和视频可用于训练目的。这一切都需要强大的数据处理能力。
2009年前后,几支AI研究团队意识到,专门用来在PC和游戏机上产生精细图像的图形处理单元(GPU)能够提供强大的数据处理能力,也非常适合运行深度学习算法。
斯坦福大学的一支AI研究团队发现,GPU可以使其深度学习系统的运行速度加快近百倍。该团队由吴恩达领导,他后来又曾加入谷歌和百度。
吴恩达
突然之间,训练一个四层神经网络只需要不到一天的时间,而以前需要好几周。GPU制造商英伟达(NVIDIA)的老板黄仁勋说,用来为玩家创造虚拟世界的芯片,也能用来帮助计算机通过深度学习技术理解现实世界。
ImageNet Challenge的比赛结果证明深度学习大有可为。突然之间,人们开始给予关注,不只是在AI圈子里,还有整个技术界。此后,深度学习系统变得越来越强大:深度达到20或30层的网络不再罕见,微软(Microsoft)的研究人员甚至打造了一个152层的网络。层数更多的网络具有更强的抽象能力,能够产生更好的结果。事实证明,这些网络善于解决非常广泛的问题。
“人们之所以关注这个领域,是因为深度学习技术具有广泛的用途,”谷歌机器智能研究主管、负责谷歌搜索引擎的约翰·詹南德雷亚(John Giannandrea)说。
谷歌正在利用深度学习来提高其网络搜索结果的质量,理解用户向智能手机发出的语音命令,帮助人们搜索包含特定影像的照片,自动生成电子邮件智能回复,改善网页翻译服务,帮助自动驾驶汽车识别周围环境。
深度学习分很多种,其中使用最广泛的一种是“监督学习”,该技术利用标记样本来训练系统。
例如,就垃圾邮件过滤而言,这项技术可能会建立一个庞大的样本信息数据库,每条样本信息被标记为“垃圾邮件”或者“非垃圾邮件”。深度学习系统可以使用这种数据库进行训练,通过反复研究样本和调整神经网络内部的权值,改善垃圾邮件的识别准确率。
这种方法的优点在于,不需要人类专家制定一套规则,也不需要程序员编写代码执行规则。系统能够直接从标记数据中学习。
使用标记数据进行训练的系统被用来分类图像,识别语音,发现信用卡欺诈交易,识别垃圾邮件和恶意软件,定向投放广告。对于这些应用,正确的答案已经存在于先前的大量样本中。
当你上传照片时,Facebook可以识别和标记你的朋友和家人。近期,该公司发布了一个系统,可以为失明用户描述照片的内容(“两个人,笑,太阳镜,户外,水”)。
吴恩达说,监督学习能够用于各种各样的数据。通过采用这项技术,现有的金融服务、计算机安全和营销公司可以贴上AI公司的新标签。
另一种技术是非监督学习,同样是使用大量样本来训练系统,但这些样本没有经过标记。系统学习识别特征和聚类相似样本,发现数据中隐藏的集合、联系或模式。
非监督学习可以用来搜寻没有具体形象的东西,比如监督网络流量模式,探测可能与网络攻击有关的异常现象,或者检查大量的保险索赔,揭露新的欺诈手法。
再举一个著名的例子。
2011年在谷歌工作时,吴恩达领导了一个名为Google Brain的项目,要求一个庞大的无监督学习系统寻找数千个非标记YouTube视频中的共有图案。
一天,吴恩达的一位博士生给他带来了一个惊喜。“我记得他把我叫到他的电脑前,对我说‘瞧这个,’”吴恩达回忆道,屏幕上有一张毛茸茸的脸,那是从数千个样本中提取的图案。系统发现了猫。
强化学习介于监督和非监督学习之间,只使用偶尔的奖励反馈来训练神经网络与环境互动。
从本质上讲,训练涉及到调整网络的权值,寻找一个持续产生更高奖励的策略。DeepMind是这方面的行家。
2015年2月,该公司在《自然》(Nature)杂志上发表了一篇文章,描述了一种强化学习系统,它能够学会玩49款雅达利经典电子游戏,只使用屏幕像素和游戏得分作为输入数据,其输出数据与虚拟控制器连接。该系统从头开始学习玩这些游戏,在29款游戏中都达到或超过了人类的水平。
DeepMind的德米斯·哈萨比斯(Demis Hassabis)说,对AI研究而言,电子游戏是理想的训练场,因为“它们就像现实世界的缩影,但更加明晰,更有约束”。
德米斯·哈萨比斯(Demis Hassabis)
游戏引擎也能非常轻松地产生大量的训练数据。
哈萨比斯曾从事电子游戏行业,后来获得认知神经科学博士学位并创建DeepMind。这家公司现在是谷歌旗下的AI研究部门,办公地点位于伦敦国王十字车站附近。
2016年3月,DeepMind研发的AlphaGo系统击败了围棋顶尖高手李世石,在五局比赛中取得4:1的压倒性胜利。
AlphaGo是强化学习系统,具有某些不同寻常的特征。它由几个相互连接的模块组成,包括两个深度神经网络,分别擅长不同的领域,就像人脑的左右半球。
其中一个网络接受的训练是分析数百万盘围棋棋局,从而在实战中给出赢面最高的几种下一步落子选择,然后交由另一个网络进行评估,后者采用随机取样的技术。因此,AlphaGo同时结合了仿生技术和非仿生技术。
关于哪种方法更好的问题,AI研究人员争论了几十年,但AlphaGo双管齐下。
“这是个混合系统,因为我们相信,我们将不止需要深度学习来解决智力问题,”哈萨比斯说。
哈萨比斯和其他研究人员已经在着手下一步,也就是迁移学习。这可以使强化学习系统把先前已获得的知识作为基础,而不必每次都从头训练。
哈萨比斯指出,人类可以毫不费力地做到这一点。詹南德雷亚回忆说,他四岁的女儿知道大小轮脚踏车也是一种自行车,即使她以前从未见过。“计算机做不到这一点,”他说。
被Salesforce收购的AI初创公司MetaMind致力于另一种相关的方法,名为多任务学习,也就是同一个神经网络架构被用来解决几种不同的问题,解决其中一种问题的经验使它能够更好地解决另一种问题。
和DeepMind一样,MetaMind也在探索模块化架构,其中一种架构名为“动态记忆网络”,能够获取一系列陈述,然后回答有关这些陈述的问题,推断出它们之间的逻辑联系(Kermit是青蛙,青蛙是绿色的,所以Kermit是绿色的)。
MetaMind还把自然语言和图像识别网络整合进同一个系统,能够回答有关图像的问题(“这辆车是什么颜色的?”)。其技术可以用于面向Salesforce客户的自动化客户服务机器人或者呼叫中心。
以前,原本形势大好的AI新技术往往会迅速失势。但深度学习不同。
“它确实很有用,”MetaMind的理查德·索赫尔(Richard Socher)说。人们每天都在使用它,但并没有意识到它的存在。
理查德·索赫尔(Richard Socher)
哈萨比斯和索赫尔等人的长期目标是打造“通用人工智能”(AGI),也就是能够处理多种任务的系统,而不是为每个问题都单独创造一个新的AI系统。
索赫尔说,AI研究多年来聚焦于解决具体狭隘的问题,但现在研究人员正在“以新的方式拼凑更先进的乐高积木”。
哪怕是最乐观的人也认为,还得再需要十年才能实现具备人类水平的AGI。但哈萨比斯说:“我们觉得,我们知道实现AGI需要哪些关键的东西。”
AI已经在发挥实际作用,并且将很快变得越来越有用。
谷歌的Smart Reply系统(利用两个神经网络自动生成电子邮件回复)在短短四个月的时间内,就从深度学习研究项目变成了现实产品(不过刚开始的时候不得不阻止它对几乎每封邮件都生成“我爱你”的回复)。
“你在学术期刊上发表论文,毫不夸张地说,随后的一个月就会有公司使用那个系统,”索赫尔说。
来自大大小小的AI公司的学术论文持续不断。AI研究人员被允许在同行评审期刊上发表他们的研究结果,即使是在转化投产之后也可以。他们中的很多人一边为企业工作,一边发表学术文章。
“如果你不让他们发表,他们就不会为你工作,”安德森-霍洛维茨基金(Andreessen Horowitz)的克里斯·迪克森(Chris Dixon)说。
谷歌、Facebook、微软、IBM、亚马逊、百度和其他公司提供了免费的开源深度学习软件。一个原因是这些公司的研究人员希望公布他们正在做的事情,这有助于招募人才。
另一个原因在于,大型互联网公司能够承担免费提供AI软件的后果,因为他们可以从其他地方获得巨大好处:获取大量用户数据用于训练目的。
投资基金Bloomberg Beta的席翁·齐利斯(Shivon Zilis)说,这使他们在某些领域具有优势。而初创公司则想办法进入特定市场。例如,无人机初创公司利用模拟数据来了解如何在拥挤环境中飞行。